I have some exciting news. Along with Gayle Laakmann McDowell, Mike Mroczka, and Nil Mamano, I’m co-writing the official sequel to Cracking the Coding Interview (often called the bible of technical interview prep)! The sequel is fittingly called Beyond Cracking the Coding Interview.
I’ve always wanted to write a book about technical interviewing. And this is it.
Technical interviews are much harder today than they used to be. Engineers study for months and routinely get down-leveled because the technical hiring bar has never been higher. Beyond Cracking the Coding Interview, in addition to covering a bunch of new questions and topics, teaches you how to think instead of memorizing. You’ll still have to do the work, of course, but we’ll teach you to work smarter.
We added thirteen new technical topics—including sliding windows, prefix arrays, and rolling hashes—and over 150 new problems ranging from popular current questions to fresh twists on the classics. Each problem includes step-by-step walkthroughs, with practice available with our online AI Interviewer. And of course this book was written in partnership with interviewing.io. We’ve pulled in data from over 100k FAANG mock interviews, and we include hundreds of curated interview replays from interviewing.io (shared with permission of course) – watch people make mistakes and learn so you’re not doomed to repeat them.
But it’s not just about interview prep. In today’s job market, the bar is higher but it’s also harder than ever to get noticed and run your job search end-to-end. My excellent co-authors killed it on the technical chapters. I focused on writing the job search stuff, including:
How to negotiate, exactly what to say, and how to not screw up your negotiations before they even start
How to manage your job search, end to end, and balance interview prep with applications and outreach
A worksheet to help you figure out what order you need to engage with the companies you’re targeting to ensure that all your offers come in at the same time
How to get in the door at top companies without relying on referrals, including email templates and examples of good and bad outreach
An internal look at FAANG (and other) company rubrics to help understand what interviewers really care about, no matter what company you’re applying to
What you need to know about behavioral interviews, whether you want to or not
Dirty secrets that recruiters and interviewers won’t tell you
A list of very specific questions to ask your interviewers (not just to look smart but to learn useful things)
How technical interviews got to be so broken and how to get over hating them so you can win
It’s everything I’ve blogged about for the last 15 years but fleshed out with much more detail and actionable advice. And of course this book was written in partnership with interviewing.io. We’ve pulled in data from over 100k FAANG mock interviews, and we have a bunch of curated interview replays for you that illustrate the points we make in the book. Watch those and learn from them (especially the failed ones).
If you read it, let me know what you think. Technical interviewing sucks (and so does looking for a job). But this book will help you navigate a difficult, broken process and get out alive.
I’m the founder of a company called interviewing.io. We’re an anonymous mock interview platform and a technical recruiting marketplace — software engineers use us for interview practice, and we connect the best performers to top companies, regardless of how they look on paper.
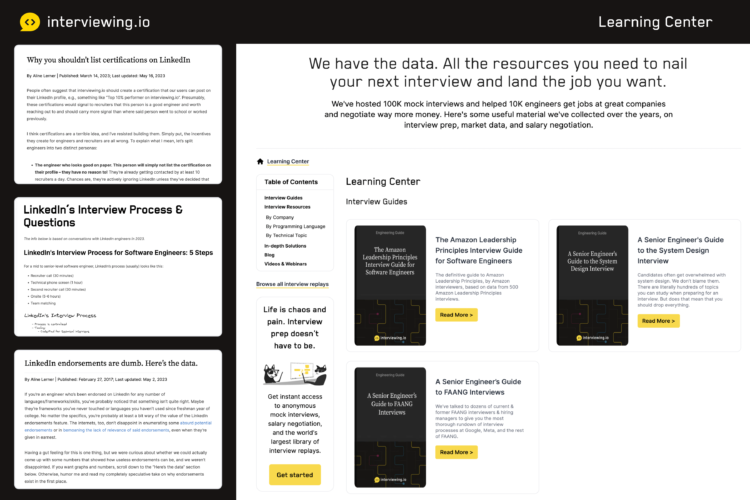
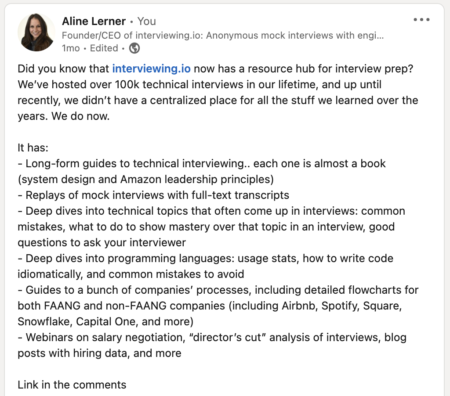
Content has always been a big part of who we are. We’ve hosted over 100k technical interviews in our lifetime, and we regularly use the data from those interviews and from our broader community, to tell stories and create interview prep resources. Recently, we published a big interview prep resource hub. After I posted about our new resource hub on LinkedIn, LinkedIn silently deleted my account and all of my company’s followers.
interviewing.io’s resource hub. It included some LinkedIn-related material, including a guide to their interview process, and a few blog posts that talked about how LinkedIn certifications and endorsements are dumb
I suspect that one or more of the following happened:
Someone at LinkedIn made a mistake that resulted in my account being banned (and likely permanently if I didn’t know someone).
LinkedIn doesn’t know who their users are. That’s poor identity management, especially for a hiring platform.
LinkedIn bans their competitors and then attempts to hide this under the guise of security practices.
I want to allow for the possibility that what happened to me was simply due to someone’s mistake. On the off chance that someone from LinkedIn does see this post and explains what happened, I commit to posting the response and, depending on what it is, completely retracting my theory.
However, if it’s either #2 or #3, it’s worth speaking out about. It’s not great that the leading hiring platform in the U.S. can’t verify the identities of its users. You can’t be good at hiring if you can’t vouch that the people showing up for the interview are the same people who applied. Given that I’m fairly well known in the recruiting space (and have been logging in from the same place for years), it’s bad if my identity can’t be verified. And if it’s not an issue of identity management but is indeed an attempt to silence other recruiting platforms, that’s definitely worth calling out.
I was ultimately able to get my account back because our investors connected me to a human at LinkedIn. But, if I hadn’t known someone, I’d probably never have gotten it back, so I want to share my story to 1) see if this has happened to anyone else (if it has, please email me: aline+linkedin@interviewing.io) and 2) maybe get some clarity from someone at LinkedIn, just in case I’m missing something — to this day, I haven’t been able to get a straight answer for what happened.
What happened?
On July 24, 2023, I published the following post on LinkedIn.
The LinkedIn post that got me deleted. Here’s the original.
After I published, LinkedIn prompted me to turn it into a promoted post. I thought, “What the hell, why not?” and gave it a $500 budget.
Now, as you saw above, our resource hub does have some LinkedIn-related content. Some of it is neutral, and some is critical of LinkedIn. Neutral content includes detailed guides for how to prepare for interviews at Google, Meta, Amazon, and other companies (LinkedIn is one of them). We also have replays of technical interviews conducted by LinkedIn engineers that other engineers can watch and learn from.
The next morning, when I tried to log in to LinkedIn, I got hit with a screen that said that my account may have been compromised and that I need to submit a photo of a government ID to verify my identity. This seemed suspect, given that I hadn’t gotten any emails from LinkedIn about suspicious sign-ins (security table stakes these days). As such, I decided not to send photos of any of my IDs.
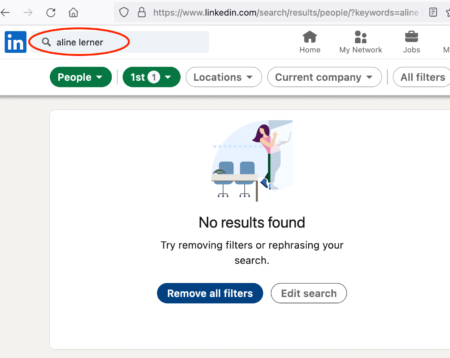
At the time, I didn’t quite put two and two together. I just assumed that I might be locked out of my account because of something to do with promoting my post. But I soon realized that there was more going on when I tried to search for myself.
For a few days, my LinkedIn profile was gone from the internet, like I never existed
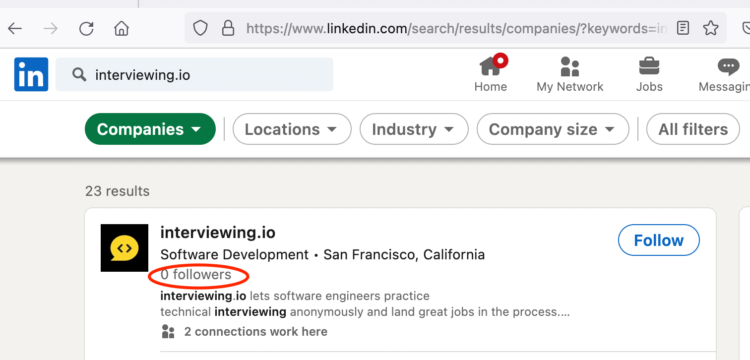
When I searched for myself on LinkedIn, this is what I saw. No results! Moreover, if you Googled me during this time and then clicked on the LinkedIn link, it would go to a dead page. Even stranger, my company suddenly had 0 followers.
Given that using LinkedIn is important for me to be able to do my job, I reached out to my network, asking if anyone knew a human at LinkedIn that I could talk to. I had tried to use LinkedIn’s support, but you need to be logged in, which resulted in a frustrating catch-22.
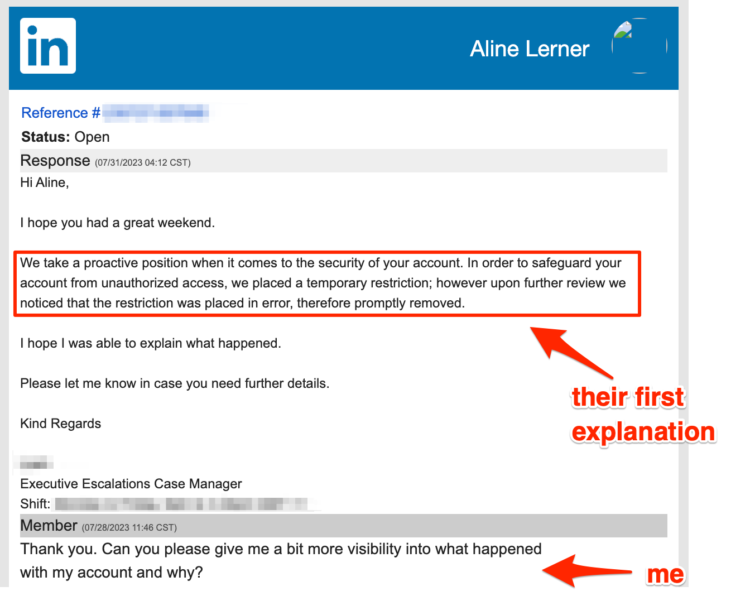
Within a day, I was emailing with a human at LinkedIn. She was a manager in a completely different department, but she escalated the issue, and two days after being deleted, I got an email from a case manager named “John” that my LinkedIn account was reinstated and had been removed in error.
I’ve blurred out “John”’s real name, their shift time, and the reference number for the case because I don’t want to inadvertently get anyone in trouble. This very likely wasn’t their fault.
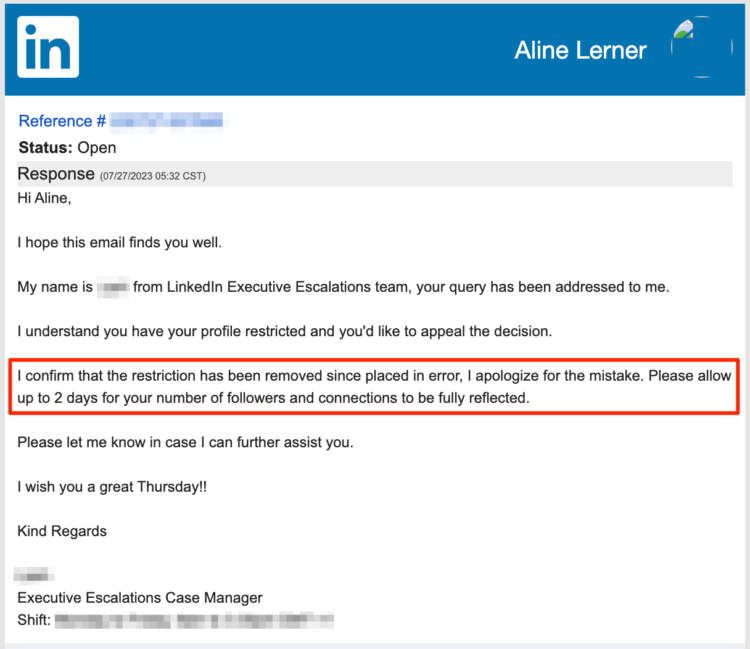
I tried to ask why I was deleted. Here’s what I learned.
If this were truly grounded in concern about the security of my account, why would my profile and all my content be gone? And why would my company suddenly have 0 followers? I asked “John” what happened and why.
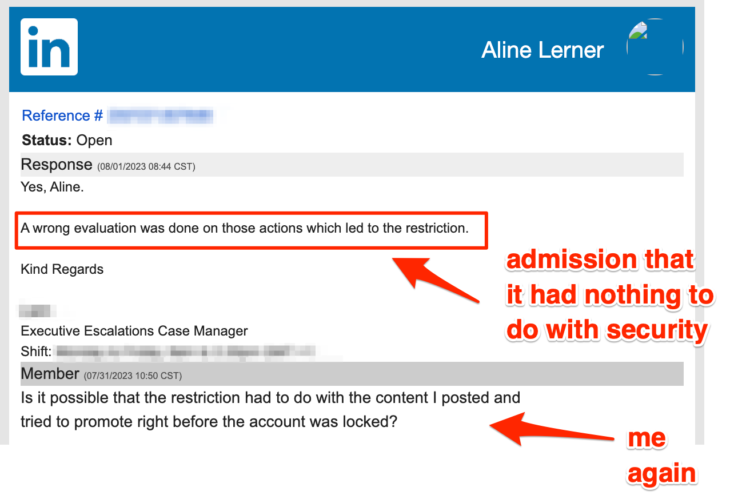
“John” reiterated the security rhetoric, as you can see above. So I pushed a bit harder. This time, I asked directly if it was about the content I posted. And it was!
Now, I can hear the skeptics saying that the “wrong evaluation” was a security evaluation and that LinkedIn’s algorithms deduced that someone hacked my account and was promoting posts (because promoting posts isn’t something I usually do). Sure, I guess that’s possible. But it’s really unlikely — after all, if that were their model, they’d be shutting down every first-time purchaser of ads, which doesn’t seem like good business.
What I think happened
Before I get into what I think happened, I want to discuss another possibility. It’s time to invoke Occam’s more cynical cousin, Hanlon’s razor: Never attribute to malice that which is adequately explained by stupidity. Now, the people who work at LinkedIn certainly aren’t stupid, but I think it’s important to acknowledge that even the best-run companies make errors or have lame policies from time to time. I want to allow for the possibility that perhaps something silly happened or that my post flagged something that is completely unrelated to interviewing.io’s business and its content. Maybe someone just made a mistake.
But… even if it turns out that my account was removed due to a misunderstanding, it’s still worth speaking up about. Here’s why. A typical LinkedIn user without connections to people who work there could end up losing their account permanently and have no ability to resolve the issue. They would lose access to their professional network, would no longer be findable to recruiters, and would no longer have access to the millions of employers that post jobs on LinkedIn. That’s a considerable price to pay for someone else’s mistake. If that’s indeed what happened, I hope that LinkedIn will revisit their policies.
However, given that not only was my personal account removed but also my company’s account suddenly had zero followers, I can’t help thinking that this time something foul was afoot, something that couldn’t be handwaved away.
In a nutshell, I think that someone on LinkedIn’s ad team saw my attempt to promote the post, decided that the post was against their terms of servicebecause it references content that derogated LinkedIn and/or shared stuff about LinkedIn’s hiring process that they didn’t want public, and proceeded to shadowban me because of it.
I took a close look at LinkedIn’s terms of service, and the only term that one could possibly accuse me of violating was the one below, because we used the word “LinkedIn” when talking about LinkedIn’s interview process as well as how useless LinkedIn endorsements and certifications are.
7. Violate the intellectual property or other rights of LinkedIn, including, without limitation, (i) copying or distributing our learning videos or other materials or (ii) copying or distributing our technology, unless it is released under open source licenses; (iii) using the word “LinkedIn” or our logos in any business name, email, or URL except as provided in the Brand Guidelines
That’s a stretch though, and it’s moot – LinkedIn must not think that I violated this term because they ended up walking back their decision to remove me.
Is it possible that LinkedIn can’t do identity management?
LinkedIn undoubtedly cares about security, but their seeming inability to identify who I am, despite me being a very vocal voice in the recruiting community and consistently logging in from the same IP address for years, speaks poorly of their identity management capability, which is kind of an important competency for a hiring platform. As the primary place where talent and employers connect, as well as a self-proclaimed up-skilling and learning platform, LinkedIn has some responsibility to be good at identity management and knowing who its users are. You can’t be a credible recruiting platform without this ability. (In the meantime, LinkedIn has no issue leaving up fake accounts that are being used for espionage.)
As it happens, we know a bit about identity management at interviewing.io — despite being an anonymous platform, we have a generally good handle on who our users are. We know how well people perform in interviews, we know how well they’re likely to perform in future interviews, and we certainly know if they are who they say they are and if their experience matches their resume. You know why we have to be good at this? Because we’re a platform that does hiring, and if we couldn’t do it, we’d be laughed out of the room. It’s implausible that LinkedIn, with all their resources and data, cannot figure out enough about their users to not demand government IDs (which they then proceed to ignore), especially when the user is a domain expert in their field.
How LinkedIn seems to do security
The fact that LinkedIn asked for my ID kept nagging at me, and I began to wonder if my situation was a common one. Fortuitously, a former interviewing.io employee also had his LinkedIn account deleted around the same time as mine. I first assumed it was because of our content. He, however, did blatantly violate LinkedIn’s terms — he changed his official name and heading to all emojis. Importantly, he experienced the same flow I did when he attempted to unlock his account. Unlike me, he complied. After LinkedIn got his ID, they informed him that he had violated their terms of service and removed him from the platform. That key detail helped me understand something about how LinkedIn does security.
So here’s what I know: users appear to get dumped into the security flow for a number of reasons (some of which may be completely orthogonal to the security of the account), and for some users (like my former employee), uploading a photo ID won’t solve it, even if the ID is legit. I don’t know if this is part of LinkedIn’s strategy or just a side effect of bad UX or bad customer service.
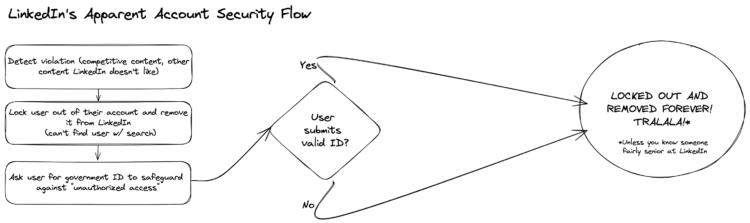
Regardless of whether it’s intentional or not, LinkedIn’s flow for any perceived violation of terms looks to be:
Lock the user out of their account
Remove the account such that it’s no longer visible on LinkedIn
Tell the user that their account may have been compromised, and ask for photo ID
Regardless of the outcome of (3), don’t undo anything and leave them locked out and deleted into perpetuity, without an explanation, UNLESS THEY KNOW SOMEONE
All in all, my experience begs the question: why is LinkedIn collecting IDs when 1) the issue isn’t a security threat but a terms violation and 2) they won’t reinstate your account whether or not you submit your ID? This all made me wonder if something more problematic was occurring, something that LinkedIn was hiding under their standardized security flow.
Anti-competitive practices masquerading as security is a dangerous pattern
Outside of the fact that I’m a paying LinkedIn user and that deleting your paying users without any explanation is kind of lame, it will be really lame if it turns out they’re trying to pass off anti-competitive behavior as a security measure.
There are a few things really wrong with the way LinkedIn seems to shadowban users. These are:
Free speech
Habeas corpus (that thing you where you can’t be held indefinitely without getting to face your accuser/a judge)
Opportunity to know what wrongdoing you’ve been accused of
Same treatment under the law regardless of social standing
Now, I can hear some of you grumbling, “Aline, habeas corpus? Come on!” I know, I know. But hang on a second. The value of these principles and how bad things get when they’re not part of a country’s guiding code and value system is something I know firsthand — I was born in the former Soviet Union. Having been on the other side, I find myself having an outsized response to violations of these principles.
Look, I know that LinkedIn is not a government institution, and as such, they are not bound to the Constitution and don’t have to operate like a court of law in the face of perceived wrongdoing by their users. This isn’t a post about how to apply the first amendment or any other amendment to corporate life. I especially know that the “free speech” argument is both nuanced and, honestly, a bit tired. Lots of people who are much smarter and better informed than I am who work in Trust & Safety at large social networks spend their careers debating what free speech means in the corporate realm.
Nevertheless, I have an especially strong immune reaction to violation of these principles in the service of silencing dissenting views, and, rather than engaging in transparent discourse, silently removing the problem as if it never existed.
It appears that LinkedIn is flagrantly silencing competitors, and rather than owning it, is masquerading their anticompetitive practices as security measures. We posted some true stuff about LinkedIn, my account was summarily removed, and my company’s followers dropped to zero. LinkedIn told me it was because there had possibly been unauthorized access to my account. If I had not found a way to talk to a human at LinkedIn, I likely would have been banned forever. That is not OK.
As such, I wrote this post to express my disappointment and to shine a light on something unethical. I’m trying to start a common-sense conversation that I hope LinkedIn’s leadership will see and, if something like this has happened to enough other people, will make them reevaluate their policies.
Now, you might argue that LinkedIn is just behaving like a normal business and that I’d do the same thing if I ran their company. Let me set the record straight. On interviewing.io, we’ve routinely hired (or offered to hire) for pretty much all of our competitors, including Indeed, LinkedIn, AngelList, Triplebyte, Hired, and others. We never messed with any companies’ rankings on our job board, never artificially put ourselves at the top, and never tried to get first dibs on the best engineers (behavior that multiple sources told me many recruiting companies engage in).
The one time we banned someone for competitive practices on interviewing.io was when the founder of a different mock interview platform joined our platform as an interviewer, and then during his interviews he tried to convince our users to switch over to his product. In that fairly egregious case, removing him from the platform seemed justified. However, we didn’t pretend to lock him out of his account because of “security measures.” We certainly didn’t ask for his government ID. We just stopped him from being able to use the product, and I told him why, directly. I don’t expect LinkedIn to call me up to explain, but I do expect them to operate by a professional code of ethics that prevents them from shadowbanning competitors.
I don’t want to win through cheating, and LinkedIn shouldn’t either. I want to win because we’ve empowered engineers to make informed decisions, and they chose us, fair and square. It’s a shame that the leading recruiting marketplace in the United States does not seem to operate under the same set of principles.
Has this ever happened to you?
I don’t think I’m alone in having my LinkedIn account shadowbanned because of something I posted. But I bet I’m one of the lucky few who was able to get back access to LinkedIn because I knew someone who knew someone. I expect most people won’t be that fortunate, so I want to help. We may not know the full picture until LinkedIn says something directly, but if enough people share their stories, we can begin to fill in the missing pieces of the puzzle.
Have you been removed by LinkedIn for something you posted? Get in touch by emailing aline+linkedin@interviewing.io. Though I’m not a journalist, I will abide by journalistic code, and if you tell me what you’re sharing is “off the record” 1) I will not reveal anything identifiable to anyone and 2) I will only use what you share in aggregate or as background information.
I’ve been in and around eng hiring for the past 13 years, as an engineer, a recruiter, and a founder of a technical recruiting marketplace (interviewing.io). Over the course of those 13 years, I’ve become increasingly disgruntled at the state of hiring, and now I’m mad enough to write this blog post.
If you’ve ever been on either end of the table, you’re probably mad at the state of hiring, too. Whether you have given it a lot of thought or whether you just feel it deep down, something about the whole process feels off.
But we’ve been doing it this way for so long that we probably take much of how hiring works as gospel, and it’s really hard to tease apart all the different components of the process and examine why they are the way they are. In this post, I’d like to challenge many of the things we assume about hiring, and, perhaps most importantly, I’d like to lay out my platonic ideal for how eng hiring should work. It’s a simple axiom, really:
It should be easy for smart people to talk to other smart people.
Or, another way to put it … if I’m a good engineer, it should be easy for me to talk to a hiring manager at a company I might be interested in, at a time of my choosing. But that’s simply not possible today. Despite the refrain that we’re in a candidate’s market and that there’s a shortage of good candidates, which should mean that candidates should have the power to call the shots, today’s hiring process couldn’t be further removed from this ideal. And it’s not just broken for a specific type of candidate. It’s broken for everyone.
If you’re reading this, you might be an engineering manager, a senior engineer with stellar credentials, a recent bootcamp grad, an engineer from a background traditionally underrepresented in tech, or some combination of these. What’s truly messed up about the status quo is that, regardless of which of these groups you fall into, your journey will be unnecessarily unpleasant. Though the degree of unpleasantness will not always be the same, it’s not about race, seniority, pedigree, or gender … or even which side of the table you’re on. Hiring, in its current incarnation, is broken for everybody.
Why? Let us go then, you and I, into the bowels of the status quo.
A candidate and a hiring manager, never the twain shall meet
Let’s say that I’m a competent generalist engineer who looks good on paper, and I’m thinking that it’s time to look for a new job. What happens next? The idea of having to mount a full-on job search is so daunting.
I could try some job boards to see which companies are out there. But what would I filter on? I know a lot of programming languages but am not set on having to work in a specific one. How can I tell if I’ll hit it off with the team? I’m applying via a job board to a position I know next to nothing about — will anyone even respond?
Suppose I find some companies where I might want to work. If I’m lucky enough to know someone there, I’ll have to get them to refer me, even though that may not actually do much to speed things along. And if I don’t know anyone there, applying will be an exhausting long shot. Odds are no one will look at my application, and having to redo my resume — or worse, write cover letters — seems like the most tedious kind of busywork.
I guess I can always dig through the recruiter spam I’ve gotten. But do those recruiters still work at the company? If they do, how long will it actually take to get into the process?
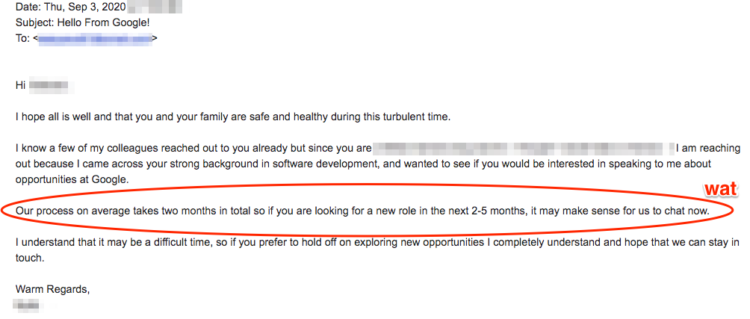
Breaking character for a moment, a friend of mine recently got this recruiting email from Google, who has elevated gaslighting to an art form: somehow the fact that it takes two months to get through their process has become a selling point.
Once I do get into the process, why do I have to endure the same intro call ten times with different recruiters who can’t tell me anything about what I’d be working on at any level of depth?
Do I join some platform, create a profile that I copy-paste everywhere (with writing that was just as painful as the aforementioned resume/cover letter) and sort of hope that decent companies contact me … only to have to begin the same recruiter calls over and over again, as above?
Will I have to take some quizzes that drill me on obscure syntax or make me solve toy problems that have no bearing on my engineering ability before I even get to have the aforementioned inane conversation with a recruiter?
If I’m actually good at my job, why can’t I just set up some conversations with companies I think are cool and see if it’s a fit? Why do I have to subject myself and others to an endless parade of vapid conversations and the inevitable busywork that precedes them?
Here’s the truth. Even if I look good on paper and am well-connected, hiring still sucks because of all the noise, uncertainty, and time wasted … but at least I have options. They might not be exactly the right options for me, but at least they exist. On the other hand, if I’m an engineer without a pedigree or a network, my choices are extremely limited, no matter how good I am. Recruiters aren’t reaching out to me, I’m not well-networked enough to have friends refer me, and I definitely don’t hear back when I apply.
Let’s take a look at the other side of the table. Let’s say I’m an eng manager who needs to hire more competent generalists for my team. Having worked as both an eng manager and a recruiter, I can tell you that what happens next isn’t particularly inspiring.
As an eng manager, I sit down with a recruiter and try to explain what I’m looking for. Nine times out of ten, I want a smart person who can get shit done. But, after a farcical game of telephone, somehow those criteria get warped into years of experience with a specific technology or requirements about where the candidate went to school. I also end up with an uninspired, sterile job description that fails to capture the imagination of any candidates who might unwittingly stumble upon it.
My recruiter then goes to any number of sourcing tools of which LinkedIn Recruiter is the ubiquitous, lackluster market leader. They type in keywords I didn’t ask for and filter on credentials I don’t care about to come up with the same homogenous list of candidates every other recruiter at every other tech company is chasing.
They then contact these candidates en masse with generic copy about my team and the hard problems we’re solving. They celebrate single-digit response rates and spend the minimal time left over to give a cursory glance at candidates applying directly.
Why is hiring broken?
So therein lies the ineffectual dance. This is the process we’ve come to accept. As far as I can tease out, the axioms that underlie today’s recruiting best practices go something like this (some of these were told to me verbatim when I was starting out as a recruiter, even):
Thou shalt not engage with active candidates. After all, in this market, strong candidates aren’t looking. Good recruiters build relationships so that when a good candidate does decide to enter the market, the recruiter is there, behind the next doorway, ready to spring!
Engineering time is expensive, so it’s critical to do as much top-of-funnel filtering as possible to make sure that it’s spent on the right candidates.
Are these axioms wrong? The sad truth is … not really. I’ve written in a previous post about how market forces rule everything around me, and recruiting best practices are no exception. In an economy with a surplus of jobs and a shortage of talent, it follows that the best talent is going to be harder to find, engineering time will be expensive, and recruiters in their current incarnation are, dare I say it, a necessary evil. 1
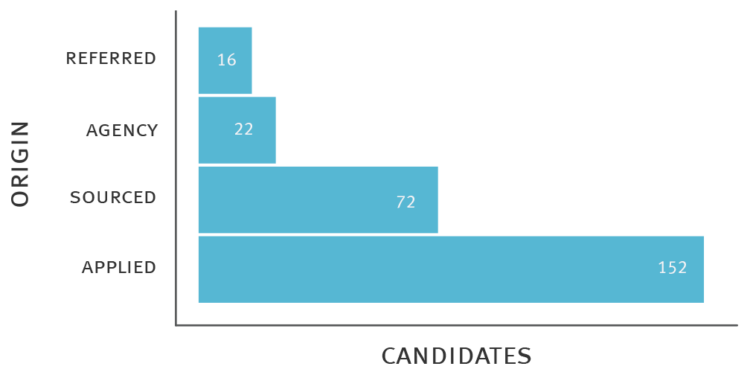
The data supports our current world view. According to Lever (one of the two application tracking systems widely used by startups, Greenhouse is the other), here’s a breakdown of how many candidates from each source it takes to make a hire. Note that here, larger numbers are bad — for many companies, internal referrals are the best source and inbound applications are the worst.
Looking at this data, you can see why recruiters simply ignore online applications. The same dynamics also apply to platforms such as AngelList — like any jobs board, it’s noisy and probably full of candidates who don’t have much leverage (e.g., juniors/bootcamp grads and people requiring visa sponsorship).
As for the value of eng time, guarding it carefully isn’t exactly wrong either. In fact, if you look at what a typical hiring process looks like today, you’ll see that most of the time spent is by engineers conducting interviews.
Hiring process stage
Who does it?
How long does it take?
Resume review
Recruiter
10-30 seconds
Recruiter screen
Recruiter
45 min
Technical phone screen
Engineer
1 hour
Onsite – Eng portion
Engineer
6 hours
Onsite – Recruiter portion
Recruiter
1 hour
Offer
Recruiter OR Eng mgr
1 hour
Engineering salaries are high, so given that most of the time spent on a single candidate is with engineers, it’s rational to put some recruiter gates at the top of the funnel to protect eng time. The idea is that recruiters will effectively screen out most candidates and only pass on the most promising ones to the eng team.
Unfortunately, when you look at an actual typical funnel, you’ll see that despite attempts to gate the top with recruiters filtering resumes and making intro calls, it’s not really working. Below is what a typical funnel looks like.
If you do the math and look at how many hours are spent — not per candidate but per hire (more useful because hires are ultimately what we want) — you’ll see that despite attempts to save eng time, recruiters spend roughly 15 hours a hire 2 and engineers spend about 40. In a process where you don’t make an offer 50% of the time and only convert those offers to hires 50% of the time, these numbers get much worse.
But, hey, recruiters are doing their best, and if we put engineers at the top of the funnel without making any foundational changes, we’d lose an order of magnitude more engineering time (and money)! So today’s approach makes some sense, even if it’s not entirely functional.
Although these approaches are rational under existing constraints, they’re neither particularly efficient nor particularly fair to the individuals subject to them. This doesn’t mean that we can’t improve the system … But before we talk about what we have the power to change, let’s dive a bit deeper into the constraints we face today.
Currently, though the market has softened a bit in the wake of COVID, we’re still in the midst of an engineering shortage. This means that eng time is expensive, which also means that, as you saw above, companies want to save eng time as much as possible. As a result, there is a palpable tension between the pain caused by the talent shortage and the expense of interviewing the wrong people.
Stacked against the backdrop of this tension lives the problem of information asymmetry. Companies don’t actually know which candidates are strong, nor do candidates necessarily know which companies are a good fit for them.
Market forces tell us that the side with less leverage will have to do the work. In a market where candidates have more leverage (they’re the ones in short supply), companies have to do the work of chasing candidates. And chase they do! In the absence of meaningful performance data, companies to a tee pursue a small subset of fairly homogenous candidates from MIT/Stanford/Google/Facebook on LinkedIn Recruiter.
And so we end up with a paradox: in the midst of a talent shortage, companies ignore the candidates who apply to them and pay recruiters without domain expertise to chase the same ten engineers with the same credentials. This is a textbook example of an inefficient market.
Perhaps surprisingly, given companies’ current constraints — market forces AND information asymmetry — the paradoxical hiring process of the status quo ends up being the logical, inevitable conclusion. This is why we have come to accept the impossibility of getting in front of a company, dealing with bad recruiters, and overlooking good non-traditional candidates.
That is the world today. But let’s imagine for a moment that you, as an engineer, had a credential, based not just on where you went to school or where you worked, both of which have repeatedly been shown to not be predictive of actual ability, but based on actual coding ability, past performance, and so on. 3 And let’s say that this credential was persistent (once you have it, it doesn’t go away). And once you got it, it awarded you the ability to be treated well in your job search.
Traditionally, market forces would dictate that I should be the one who is courted, but if my “pursuit” isn’t a waste of time but actually an efficient, useful signal-gaining interaction, then why doesn’t it make sense for me to initiate contact with companies? After all, companies don’t know when I’m looking. Historically attempts to identify when candidates flip from “passive” to “active” haven’t been effective (the now defunct Entelo Sonar is an example), so if the act of contacting a company is useful to me and puts me in the driver’s seat, why wouldn’t I do it? Remember, when we’ve solved for credentialing and companies know I’m a worthwhile investment, they’re not going to treat me poorly.
In a world with functional credentialing, putting candidates in the driver’s seat makes sense. After all, candidates are the only ones who know when they’re looking. So why shouldn’t they be able to act on that? Instead of them chasing companies, call it doing non-committal recon … and then, once things get more serious, in a market with a shortage of candidates, companies will still be the ones doing the chasing.
Put simply, when we have functional credentialing, when we disintermediate recruiting, and put candidates in the driver’s seat, we suddenly have an efficient, liquid marketplace. So, if it’s that easy, do solutions like this exist? And do they work?
Isn’t this problem being fixed already? A brief history of hiring solutions, and how everyone eventually becomes LinkedIn Recruiter
Sadly, no, though it’s a problem that many smart people have tried to tackle by building products. Historically, these products have been variants of LinkedIn Recruiter, some with more window dressing than others. Several companies tried to be different but eventually succumbed to the inevitability of the LinkedIn Recruiter model. Three examples you might be familiar with are:
Hired
Triplebyte
AngelList
What’s the problem with these solutions? There are two common threads:
Lack of credentialing: Most of them don’t have reliable performance data, or if they do, they never got companies to trust it enough (thereby not addressing the problem of information asymmetry), and these platforms typically don’t allow candidates to take charge of their own job search.
Lack of candidate autonomy… and too many middlemen: Today, hiring is owned by recruiters who sit between companies and candidates, and hiring platforms are no exception: most of these platforms don’t allow candidates to contact companies when they’re interested. It’s not bad for companies to do outreach, but candidates know best when they’re looking. As we noted earlier, though market forces tell us that companies have to do the chasing, it is far more efficient for candidates to initiate contact. Unfortunately, most of these platforms actually make the process less efficient by adding an extra hurdle: requiring candidates to interact with a recruiter who works for the platform before speaking with a recruiter at the company in question before finally meeting with an engineer. Hired called recruiters who worked for them “talent advocates,” and Triplebyte named them “talent managers,” but they’re simply other names for recruiters, just like you’d have at an agency.
These problems feed off each other, and failing to address them makes it impossible to build a solution where it’s easy for smart people to talk to other smart people.
Hired
Hired is a technical recruiting solution probably everyone has heard of. Hired has gone through a few evolutions, but when it started, it was called DeveloperAuction and only accepted candidates from MIT/Google/Facebook/Stanford, etc., allowing companies to “bid” on engineers before ever interviewing them.
DeveloperAuction’s goal, as I understand it, was to align hiring with market forces. Candidates have more leverage in the market (as we discussed earlier), so DeveloperAuction decided to call a spade a spade and actually give candidates that power by literally having the “weaker” party place bids.
Hired’s/DeveloperAuction’s approach ran into both of the aforementioned roadblocks: lack of credentialing and lack of candidate autonomy.
Lack of credentialing was problematic because: 1) pedigree isn’t a reliable indicator of performance in the first place, and 2) once Hired exhausted their initial Stanford et al. pool, they didn’t have a reliable means of credentialing to separate the good candidates from the bad. In addition, companies weren’t reliably bidding on all candidates, concentrating instead on a small pool of candidates who were often not interested in the companies that were bidding on them.
Hired tried asking job seekers to take quizzes, but of course only the people who needed to take them actually did so, which meant mostly juniors, folks with visa constraints, or people who didn’t look good on paper (some of whom were of course diamonds, but that’s not enough to build a business around).
The second problem, lack of candidate autonomy, came to light because pretty quickly Hired realized that (due to lack of meaningful credentialing) companies typically bid on the same ten people, and those ten people, because of how many options they had, weren’t interested in most companies. To mitigate these issues, Hired brought on an army of “talent advocates” (read: recruiters) whose job it was to prime the pump and ensure that companies were bidding on the “right” candidates behind the scenes.
Now, as a candidate, not only do you have to talk to an in-house recruiter, but you have to talk to Hired’s recruiter before that!
Of course, employing an army of recruiters makes achieving SaaS margins impossible, and, before you know it, you’re basically a tech-enabled recruiting firm.
Eventually, Hired moved away from the auction marketplace model, fired most of their talent advocates, and fulfilled their destiny, becoming a glorified LinkedIn Recruiter clone. Recruiters could search for candidates, just like on LinkedIn Recruiter, based on their pedigree, languages they knew, etc. Being a LinkedIn Recruiter is a business with better margins, and it’s a model that makes the middlemen who hold the purse strings — the in-house recruiters — feel empowered, which perpetuates the market inefficiency we identified earlier.
Triplebyte
Triplebyte’s story started out completely differently. They wisely rejected pedigree as a viable means of credentialing and adopted the admirable mission of democratizing access to opportunity in software engineering.
As Triplebyte was a YC company, they started out as “the common application for engineers who wanted to work at a YC startup.” To ensure that candidate quality was high, Triplebyte came up with a two-step vetting process: the first was a coding quiz anyone could take. If you did well on the quiz, then you conducted a lengthy technical interview with one of Triplebyte’s contractors. Triplebyte brought on a number of engineers to conduct these interviews, and they also created their own canonical technical interview that every candidate had to complete. If you did well in the interview, regardless of how you looked on paper, you got fast-tracked to onsites at Triplebyte’s customer companies.
Triplebyte, to my mind, did an admirable job of trying to solve the credentialing problem. But their approach was not without shortcomings: 1) not everyone wanted to take their lengthy quiz, even though the quiz was well done, and 2) scaling up an army of interviewers, all of whom had to be trained in exactly the same way, was non-trivial and not cheap. These challenges were surmountable, but the challenge that wasn’t arose from the second issue that all companies had to face: lack of candidate autonomy, which was driven in part by a lack of faith in the credential.
Once you passed Triplebyte’s assessment process, just like at Hired, you had to interact with a talent advocate (Triplebyte labeled them “talent managers,” but again they’re just recruiters). The talent manager would examine your background and short-list you for some companies of their choosing, where you’d then go onsite. You could have some input into which companies you spoke to, but it was limited, and if you didn’t meet the company’s (often somewhat arbitrary) criteria, no matter how well you did on the assessment, its doors were closed to you.
As with Hired, having an army of recruiters AND interviewers working for you makes achieving SaaS margins impossible, and then, you’ve essentially become a tech-enabled recruiting firm (albeit this time one with much better performance data!).
Just like Hired, Triplebyte eventually moved away from the auction marketplace model, fired most of their talent managers and interviewers, and fulfilled their destiny, becoming a glorified LinkedIn Recruiter clone. Recruiters could search for candidates, just like on LinkedIn Recruiter, based on their pedigree, languages known, and so forth. One thing Triplebyte still does differently, however, is to leverage their aforementioned coding quiz to annotate candidate profiles. (Presumably, they are using their historical interview data, from when candidates had to do BOTH, to predict how people will perform in interviews.) The limitation, of course, is that great people will be unlikely to take the quiz in the first place, especially now that it no longer fast-tracks them to an onsite.
AngelList
My last example is AngelList. AngelList is a bit different from Tripleybte and Hired because they have not fully succumbed to becoming a search aggregator, probably because AngelList’s main revenue driver isn’t their recruiter business but their angel investment marketplace.
The big difference between AngelList and the others is that AngelList does give candidates autonomy — you can apply to any company of your choosing — but without the credentialing piece in place, it’s toothless. As with their inbound channels, companies have learned to ignore AngelList referrals because they’re noisy and full of candidates who don’t have much leverage (again, juniors/bootcamp grads and people requiring visa sponsorship, for example).
Currently, AngelList has some early attempts at credentialing in place, mostly quizzes that self-select out people who don’t need to take them. Because their credentialing lacks weight, when a candidate reaches out to a company on AngelList, they aren’t fast-tracked. It’s just like applying via an online job board.
When I was doing research for this piece, one quote about AngelList stuck out (specifically, it was about the now-defunct A-List offering), speaking poignantly to the importance of removing the barriers between candidates and companies during the hiring process. It’s nice when it’s easy for engineers to talk to engineers.
How to fix hiring
As you can see, historically, recruiting solutions have been plagued by two limitations: lack of credentialing and lack of candidate autonomy and resulting middlemen. What happens if you remove them and build something free of these restrictions?
In this beautiful world, once I’ve established that I’m smart and can get shit done, doors of companies are open wide to me. Imagine this. I scroll through a list of employers, pick one that I’m interested in, bypass all the bullshit that typically happens at the top of the funnel — the scheduling, tedious recruiter calls, resume reviews — and I just get to talk to an engineer at that company. Maybe I’m not sure I want to work there yet, and that’s fine. But this way, I get signal about whether I want to, in a way that talking to a recruiter or reading a job description simply can’t replicate.
And I don’t have to wait for recruiters to find me on LinkedIn or in Triplebyte or some other search aggregator, then contact me, all while hoping that the chaotic universe somehow delivers a reachout from a recruiter at a company I actually want to work for at the right time. Or that the recruiter who reached out to me when I wasn’t looking a year ago still works there. But odds are they don’t.
There’s no substitute for chemistry, in dating or in hiring. All the carefully crafted job descriptions in the world pale in comparison to talking shop with someone on the team. That’s how it should be.
In this new world, even though there’s still an engineering shortage, with the advent of persistent, meaningful credentialing and candidate autonomy — the two limitations that have plagued hiring solutions to date — can we now overturn the two “axioms” that have so hampered recruiting? Here they are again:
Thou shalt not engage with active candidates. After all, in this market, strong candidates aren’t looking. Good recruiters build relationships so that when a good candidate does decide to enter the market, the recruiter is there, behind the next doorway, ready to spring!
Engineering time is expensive, so it’s critical to do as much top-of-funnel filtering as possible to make sure that it’s spent on the right candidates.
Let’s look at #1 first. Does this still hold? No! Now, when candidates are active, they can just approach companies they’re interested in. No more skulking and waiting and guessing and writing software that tries to predict when passive candidates are on the move.
How about #2? Nope. Now that candidates come vetted, putting up artificial gates to save eng time doesn’t make sense anymore. If anything, putting up gates would now be an antipattern because it delays the sell — the sooner you can get an engineer talking to an engineer about The Work, the better.
Now, as a candidate I’m actually in the driver’s seat. I can talk to companies I’m interested in learning more about, at any time, without all the hurdles and frustrations that define the current process.
Why do I feel so strongly about all of this? It’s exactly what we’re working on at interviewing.io. At this point, you might roll your eyes and say, what a cheap plug. Or wonder why we think we can succeed where so many others have failed. But, before you do, think on this. I’ve spent the last five years of my life dedicated to bringing this vision of hiring to fruition because I believe, in my heart of hearts, that this is the only way hiring can be both efficient and fair. If I didn’t talk about the thing I made which addresses this very problem, and if I didn’t believe in it to the point of fanaticism, I’d be a raging hypocrite. And if I weren’t proud enough of what my team and I have achieved to promote it, then I’m doing everything wrong.
Or, hell, we could be completely mistaken about our approach… being contrarian doesn’t necessarily make you right in the long run. Hell, maybe devolving to LinkedIn Recruiter is the only way. But, look, I really hope not.
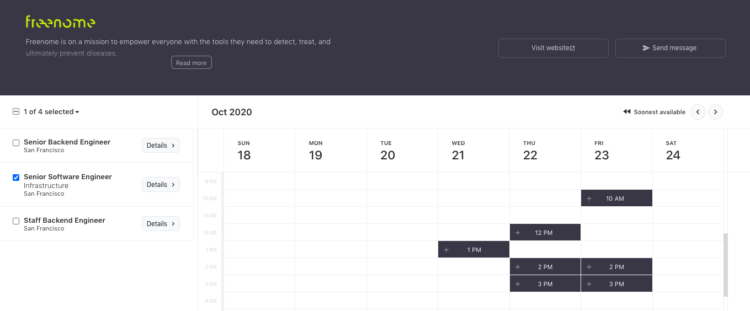
In any event, on interviewing.io, once you’ve built up your reputation by doing mock interviews (persistent, meaningful credentialing), you can look through a list of companies, and regardless of who you are or how you look on paper, you can book an interview with an engineer at that company as early as the next day (candidate autonomy and a direct line to an engineer).
You can pick companies you’d like to talk to… …and grab a time slot that works for you. There’s an engineer on the other end. No recruiters or resumes.
It feels like magic when it works, and 40% of our hires have been people whose resumes you probably wouldn’t pick out of a lineup (in fact, many had been rejected due to their resume by the very same company that eventually hired them through us). The remaining 60% of our hires are people who look great on paper but were fed up with the Kafkaesque dog and pony show that traditional hiring has become.
Of course, one of the limitations of our approach is that we’re getting performance data about engineers from the practice interviews they do on our platform. Any seasoned interviewer will tell you that the signal one gets from a technical interview isn’t the whole story. A candidate’s performance can oscillate from interview to interview, some candidates are less familiar with the format, the system can be gamed by memorizing Leetcode problems, and so on. But it’s a start, and we’ve found that data in aggregate (performance in at least three interviews) is much more predictive than a single data point. Interview performance aside, we hope to build a corpus of data about people that goes beyond how they do in interviews and also tracks how they perform on the job.
All I want is a world where it’s easy for smart people to talk to each other. That’s the world we’re trying to build at interviewing.io.
From what you’ve read up until this point, you might think that I hate recruiters and find them useless. Not so, dear reader! I hate bad recruiters. And, unfortunately, most of them are bad. What’s sad is that the good ones, instead of spending time on tasks for which they’re uniquely qualified and well-suited, are instead stuck at the top of the funnel sourcing engineers whose qualifications they don’t have the domain expertise to evaluate and selling them on roles they don’t have the domain expertise to describe. The best recruiters I’ve worked with are singularly amazing at shepherding candidates through the process, tirelessly stewarding a company’s employer brand, advising hiring managers on the best ways to close, keeping an analytical eye on the funnel to identify issues before they even arise, and much more.↩
If we add in time to review resumes, it’s an extra five hours (at most).↩
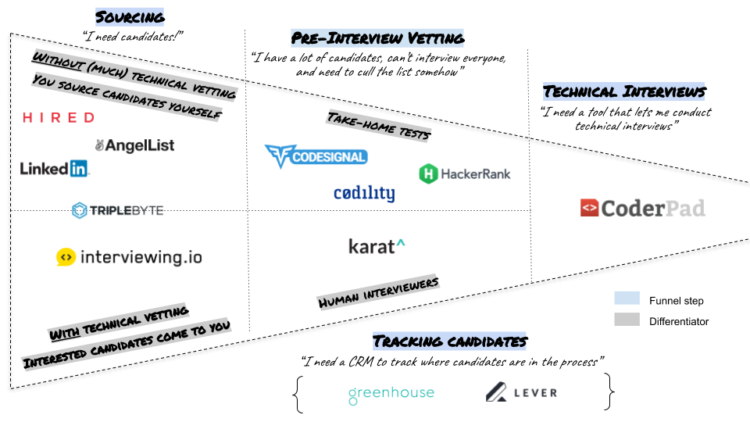
I get a lot of questions about which hiring tools do what and how they’re different from each other, so I decided to draw an ugly, yet handy, picture (see below).
By the way, the reason this post has “unbundled” in the title is that many hiring tools, in part because we’re all on the VC funding treadmill, aspire to be more than they are and to ultimately be the one ring that rules them all, all the way from sourcing to interviewing to reference checks to onboarding to god knows what. So far, these attempts at grand unification, much like communism, have not panned out in practice. Though most tools claim to do more, most do more badly 1 but will try to upsell you on how they can solve all your hiring needs. Therefore, in the picture above, I’ve chosen the primary use case for each tool, i.e. the use case that each tool has actually gotten traction for (and the use case that I believe they’re actually good at).
And last thing. I run interviewing.io, which means that my take on other tools is indiscriminately biased. But, hell, it’s my blog, and I can say whatever I want… and having been in this industry for almost 10 years as an engineer and later as both an in-house and an agency recruiter and having spent the past 5 years running a successful hiring marketplace, I have acquired my prejudices the honest way, through laboratory experience. 2
All that said, a few of the choices I made in the picture probably require some explanation, so here goes…
I thought HackerRank also had an interview tool. Yep, they do, it’s called CodePair. However, last I checked, in order to use it, you also had to buy other things, i.e. you can’t just use CodePair for technical interviews without buying in to the broader HackerRank ecosystem. And though CoderPad isn’t paying me for this, I think it’s a superior tool on many levels (and the one we actively chose to use inside of interviewing.io, forsaking all others). CodeSignal also has their own tool and Codility does as well, but that’s kind of the point of this post: tools unbundled. I’m listing the tools that have the differentiator in question as their core competency, not an add-on on some enterprise checklist.
Why is Triplebyte in the middle of the sourcing section? Triplebyte recently pivoted to a new model. Instead of interviewing their candidates before sending them to customers, they now rely on a quiz, the results of which they use to annotate candidate profiles that recruiters can source from. Before that, they had their own interviewers conduct technical interviews with candidates and also had their talent managers match candidates to companies.
I thought Hired, AngelList, and LinkedIn had some kind of skills assessment/technical vetting? They do, but last I checked it was an asynchronous test (rather than a human interviewer). In my opinion, asynchronous skills testing on these platforms has some value, but it’s quite limiting for a few reasons:
Skills testing for candidates is optional on these platforms, which means that 1) not all profiles are vetted and 2) you get a good amount of selection bias for candidates without leverage taking them, e.g. juniors and people who need new visa sponsorship
Much easier to cheat
And of course asynchronous tests are lower fidelity than human interviewers (or at least the ones I’ve seen to date… but I want to be proven wrong)
I thought AngelList had interested candidates come to you? They do. But like any jobs board, it’ll be noisy and probably full of candidates who don’t have much leverage, e.g. juniors/bootcamp grads and people requiring visa sponsorship.
Should I use take-home tests in my process? As with many of my answers, it’s a matter of leverage. Candidates who have lots of options probably won’t spend time on take-homes. Candidates who don’t, either because they’re junior or because they don’t get a lot of recruiter outreach for other reasons, will.
Why are you so obsessed with leverage? Because market forces rule everything around me.
Hey, if you do sourcing, why does your company literally have “interviewing” in the name? The way we get candidates into our ecosystem is by offering them mock interviews. Then top performers from our practice pool can choose to use us for their job search. The name originally was meant to highlight the practice offering, but yeah, it’s confusing.
Is interviewing.io a good way to source candidates? Yes. Yes it is.
The bit about acquiring your prejudices the honest way is one of my favorite quotes, and credit goes to James Roberge, electrical engineering professor at MIT.↩
Many of them ask about bootcamps. Almost all are surprised by the harsh reality that, though bootcamps can be a perfectly useful and valid start to your career change journey, they are not the magical panacea that they purport to be… and that a true career change is going to take a lot of blood, sweat, and autodidactic tears after graduation for most people.
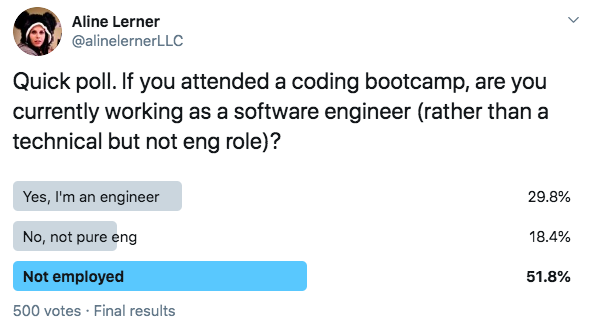
Why do I believe this? A few reasons. First, I did a Twitter straw poll about post-bootcamp outcomes a while ago, and it was pretty grim:
Of course, Twitter straw polls aren’t science or even really data. What *is* data is how bootcamp grads perform in technical interviews. At interviewing.io, we’ve run pilots with most reputable programs at one point or another, hoping that we’d be able to place their students. The sad truth is that almost every current bootcamp student who participated in interviewing.io’s mock interview pool failed.To be fair, our audience is usually senior engineers, but interviewers see candidate seniority and do adjust question difficulty. Despite that, the outcomes were not encouraging.
It’s not that the students don’t have potential. It’s that every program I’ve seen doesn’t dedicate nearly enough time in the curriculum to interview prep. Technical interviews are hard and scary for everyone, even FAANG engineers with 5+ years of experience. The idea that you can teach someone who’s never coded before big O notation AND get them proficient at writing efficient code and articulating trade-offs in 2 weeks (this is how long I’ve heard the most reputable programs spend on technical interviewing) is laughable.
So, without further ado, for those of you considering attending a bootcamp, these are the questions you should ask.
Do you ask people to leave before graduation if they’re struggling?
Does your job placement rate include just graduates?
Is your job placement rate an average of all cohorts or just a few/the best ones?
What is considered “getting a job”? Does it include people who are working on contract or part-time? Does it include people who are now TAs or instructors at the bootcamp? Does it include people who found work doing something other than software engineering?
What is the median salary of grads (not just the average)? And do those numbers include part-time work/other job titles or just full-time software engineers?
For the students who ended up at FAANG, what were their backgrounds? Were they electrical engineering majors? Physics students? What portion of people who ended up at FAANG didn’t know how to code before doing the bootcamp?
What portion of your curriculum is dedicated to technical interview prep?
How many mock interviews with industry engineers (not peers or instructors) will I get as part of the course?
Let me know if these questions help you in your adventures, brave heroes. Another resource you can use is the CIRR — they’ve created a standardized request form that bootcamps can use to report outcomes, and you can see outcomes from participating bootcamps for H2 (second half) of 2018. It’s not everything, but it’s a start.