Note: This post was adapted from an answer I wrote on Quora.
EDIT: I’m working on something that I hope will make things better. Check out interviewing.io.
I’ve been hiring people in some capacity for the past 3 years. First, I was doing it as an engineer, then as an in-house recruiter, and now as the owner of my own technical recruiting firm. Until recently, I was quite sure that the startup world was as meritocratic as something could reasonably be.
I was wrong. Most hiring managers pay lip service to how they’re looking for strong CS fundamentals, passion, and great projects over pedigree, but in practice, the system breaks down. The sad truth is that if you don’t look great on paper and you’re applying to a startup that has a strong brand, unless you know someone in the company, the odds of you even getting an interview are very slim.
People focus on the technical interview itself as a potential source of unfairness in the hiring process, but I’m going to focus on something that I think is even more of a problem: just getting your foot in the door.
How the system breaks down
Let’s say you’re the technical co-founder of a new startup that has had some traction, and there’s a backlog of work piling up. Fortunately, you’ve raised enough money to hire a few engineers. Chances are, you’re the sole technical person, so you’re probably the one working on engineering recruiting full-time. This sucks a bit for you because it’s likely not what you think you’re best at, and it sucks a bit for the company because of opportunity cost. However, you’re probably doing a pretty good job because 1) you’re really good at selling the vision of the company because you’re so vested in it and 2) you have the technical chops and intuition to evaluate people based on some set of internal heuristics you’ve acquired through experience. Because of these heuristics, you’re probably going end up letting in people who seem smart even if they don’t look great on paper.
Eventually, things are going well, your startup gets some more funding, and you decide you want to go back to doing what you think is real work. You hire an in-house recruiter to deal with your hiring pipeline full-time.
This is where things start going south. Because recruiters are, generally speaking, not technical, instead of relying on some internal barometer for competence, they have to rely on quickly identifiable attributes that function as a proxy for aptitude. OK, you think, I’m going to give my recruiter(s) some guidelines about what good candidates look like. You might even create some kind of hiring spec to help them out. These hiring specs, whether a formal document or just a list of criteria, tend to focus on candidate attributes that maximize on odds of the candidate being good while minimizing on the specialized knowledge it takes to draw these conclusions. Examples of these attributes include:
- CS degree from a top school
- having worked at a top company
- knowledge of specific languages/frameworks1
- some number of years of experience
This system works… sort of. If your company has a pretty strong brand, you can afford a high incidence rate of false negatives because there will always be a revolving door of candidates. And while these criteria aren’t great, they clearly perform well enough to perpetuate their existence.
Unfortunately, this system creates a massive long tail of great engineers who are getting overlooked even in the face of the perceived eng labor shortage.
What about side projects?
Folk wisdom suggests that having a great portfolio of side projects can help get you in the door if you don’t look great on paper. I wish this were more true. However, unless your side project is high profile, easy for a layperson to understand, or built with the API of the company you’re applying to, it will probably get overlooked.
The problem is the huge variety of side projects, and how indistinguishable to appear to a non-technical recruiter. To such a person, a copy-and-pasted UI tutorial with a slight personal spin is the same thing as a feature-complete from-scratch JavaScript framework. Telling the difference between these kinds of projects is somewhat time-consuming for someone with a technical background and almost impossible for someone who’s never coded before. Therefore, while awesome side projects are a HUGE indicator of competence, if the people reading resumes can’t (either because of lack of domain-specific knowledge or because of time considerations) tell the difference between awesome and underwhelming, the signal gets lost in the noise.
To be clear, I am not discouraging building stuff. Building stuff on your own time is a great way to learn because you run into all sorts of non-deterministic challenges and gotchas that you wouldn’t have otherwise. Few things will better prepare you for the coding interviews that test if you know how the web works, have decent product sense, can design DB schema, and so on. It’s just that having built stuff is no guarantee of even getting your foot in the door.
What can we do about this?
Bemoaning that non-technical people are the first to filter candidates is silly because it’s not going to change. What can change, however, is how they do the filtering. There are a few things I can think of to fix this.
- Figure out which attributes are predictors of success, going beyond low hanging fruit like pedigree. This is hard. I tried to do it, and Google’s done it. I wish more companies did this kind of thing and published their results.
- Find other ways of evaluating candidates that are at least as cheap and effective as resume filtering but are actually more primary indicators of competence.
- Establish a free/low-cost elite set of CS classes that anyone can get into but that most cannot complete, because of the classes’ difficulty and stringent grading. Build this into a brand strong enough for companies to trust. This way merit can effectively be tied to pedigree. This is also really hard. I know a number of companies are attacking this space, though, and I am excited to see how hiring will change in the next few years as a result.
My second suggestion is the one I will talk about here because it’s the least hard to implement and because pieces of it are already in place.
To avoid being judged on pedigree alone, in lieu of the traditional resume/cover letter, applicants who don’t look great on paper could apply to a specific company with 1) a coding challenge and 2) a writing sample.
Ideally the coding challenge could be scored quickly and automatically. It should also be an interesting problem that gives some insight into the company’s engineering culture and the kinds of problems they’re solving rather than a generic FizzBuzz. If the coding challenge is too textbook, a certain subset of smart people aren’t going to want to waste their time on it. Tools to automate coding evaluation already exist (e.g. InterviewStreet, Codility, and Hackermeter), but they’re not currently baked into the application process the right way. In the case of InterviewStreet and Codility, candidates have to already be in a given company’s pipeline to be able to work on the coding challenges, which means that anyone who looks bad on paper will be cut before getting to write a single line of code. In the case of Hackermeter, candidates code first and hope to be matched up with a company later. This approach has a lot of potential, but unless Hackermeter can establish themselves as the definitive startup application go-to, candidates will always be limited by Hackermeter’s client list. The ideal solution will probably be a more decentralized version of Hackermeter that companies can administer from their jobs page.
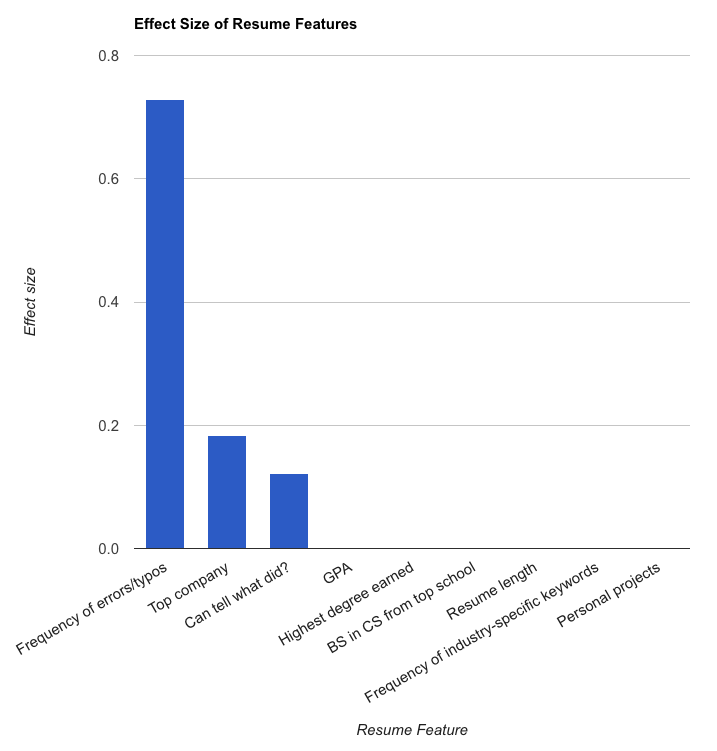
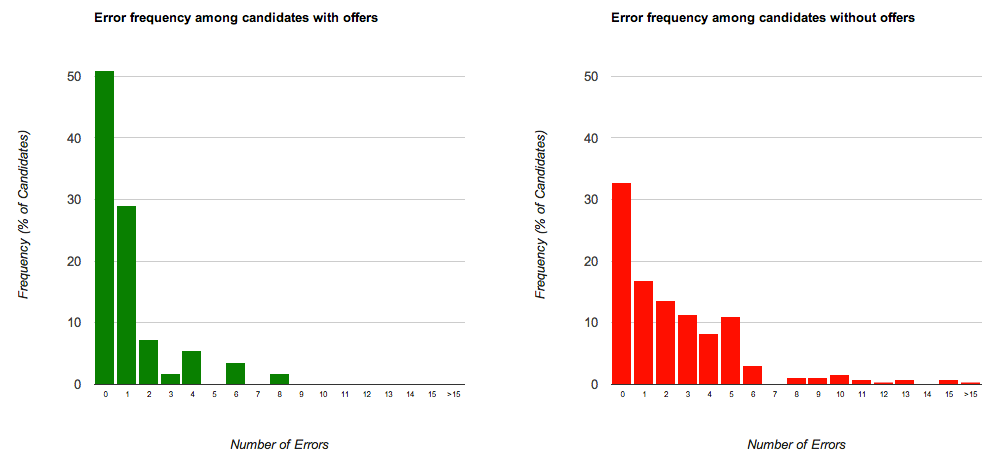
The idea for the writing sample came from the study I conducted. Of the many attributes I tested, the three that achieved statistical significance were grammatical mistakes, whether the candidate worked at a top company, and whether you could tell from their resume what they did at each of their previous positions. Two out of the three attributes, in other words, had to do with a candidate’s written communication skills.
For the writing sample, I am imagining something that isn’t a cover letter — people tend to make those pretty formulaic and don’t talk about anything too personal or interesting. Rather, it should be a concise description of something you worked on recently that you are excited to talk about, as explained to a non-technical audience. I think the non-technical audience aspect is critical because if you can break down complex concepts for a non-technical audience, you’re probably a good communicator and actually understand what you worked on. Moreover, recruiters could actually read this description and make valuable judgments about whether the writing is good and whether they understand what the person did. If recruiters can be empowered to make real judgments rather than acting as a human keyword matcher, they’d probably be a lot better at their jobs. In my experience, many recruiters are very smart, but their skills aren’t being used to their full potential.
The combination of a successfully completed coding challenge and an excellent writing sample should be powerful enough to get someone on the phone for a live coding round.
The problem of surfacing diamonds in the rough is hard, but I think these relatively small, realistic steps can go a long way toward helping find them and make eng hiring into the meritocracy that we all want it to be.
1This is definitely very relevant for specialized roles, but I see it a lot for full-stack generalist kinds of roles as well