People often ask me if I’m a talent agent for engineers, in the same way that actors have talent agents in Hollywood. In a lot of ways, the way I work is closer to a talent agent than a traditional recruiter — rather than sourcing for specific positions, I try to find smart people first, figure out what they want, and then, hopefully, give it to them.
However, I’m not a talent agent in the true sense, nor have I ever met any. I really wish the agent model could work, but in this market, it’s not going to happen. Here’s why.
First, some quick definitions. A talent agent is paid by people looking for work. A recruiter is paid by companies looking for people. If someone tells you they’re a talent agent for engineers, ask them where their paychecks are coming from.
Agents make sense when it’s hard to find a job or when the opportunity cost of looking for work is high enough to justify paying someone else. Recruiters make sense when it’s hard to find workers or the opportunity cost of looking for workers is high enough to pay someone else. In some sense, it’s almost like recruiters are talent agents for the companies they’re representing.
Talent agents for actors make a lot of sense for precisely this reason. According to the Bureau of Labor Statistics (BLS), “employment of actors is projected to grow 4 percent from 2012 to 2022, slower than the average [of 11%] for all occupations.”1 By contrast, “employment of software developers is projected to grow 22 percent from 2012 to 2022”2, about twice as fast as the average. To get a better handle on this disparity, I also tried to pull current unemployment figures for each industry. Based on some quick googling, it appears that unemployment for software engineers is somewhere between 1 and 4% depending on the source. For actors, it’s between 27 and 90%. What was particularly telling is that according to BLS, there are something like 67K acting jobs in the U.S. (the figure was for 2010 but based on projected growth, it’s not changing too much). The Screen Actors Guild‐American Federation of Television and Radio Artists (SAG-AFTRA) alone boasts over 165K members3, and The Actors’ Equity Association (union for stage actors) has about 50K members4.
Where competition for a job is extremely fierce, it’s in your interest to pay someone a portion of your salary to legitimize you and help get you the kind of exposure you wouldn’t be able to get yourself. For engineers, because the shortage is in labor and not jobs, paying out a portion of your salary for a task you can easily do yourself doesn’t make much sense. Sure, having to look for work on your own is kind of a pain in the ass, but it’s not something you do that often, maybe once every few years. And, in this market, finding a job, for desirable candidates who would actually be in a position to have talent agents clamoring for them, is not that tough. If you look good on paper and have an in-demand skill set, you can pretty quickly end up with a compelling lineup of offers. Even if you do get a few more offers with an agent, for most people, interview exhaustion sets in at somewhere around 5 on-site interviews. Moreover, from what I’ve been able to observe, most people are looking for a job that’s good enough. After a while, if the company is above some social proof threshold, the work seems interesting, the people are cool, and you’re getting paid well (with the supply/demand curve looking the way it does now, this isn’t currently a problem), then you accept.
I found this out myself when I first started my own recruiting firm. At the time, I really wanted to explore the talent agent model. I was convinced that having engineers pay for an agent’s services would swiftly rectify many of the problems that run rampant in technical recruiting today (e.g. wanton spamming of engineers, misrepresentation of positions, recruiters having a very shallow understanding of the space/companies they’re recruiting for), so I spent the first few months of running my business to talking to engineers and trying to figure out if a talent agent model would work. Engineers were super excited about this. Until I mentioned the part where they’d have to pay me, that is.
It does bear mentioning that freelance engineers do have talent agents (e.g. 10X Management). When you’re a freelancer, you’re switching jobs and often and potentially working several jobs in parallel, and on top of that, your time is split between doing actual work (coding) and drumming up business, so the less time you spend on drumming up business, the more time you can spend doing work that pays. In this model, paying someone to find work for you makes perfect sense because the opportunity cost of not working is high enough to justify the payment.
There are some full-time engineer archetypes for whom having a talent agent might seem to make sense. There are people who still have trouble finding work in the status quo. Examples might be engineers who:
don’t look good on paper but are actually very good
are looking for a really specific niche (e.g. NLP engineer looking to work on high-volume search with a specialty in Asian languages)
However, there are not enough of these people to justify an entire market. In other words, for a lot less effort and a lot more money, you could just focus on more mainstream candidates and get paid by the company.
All that said, I wish the whole talent agent thing could work because then the ethics would align with the money. And that’s kind of the dream, isn’t it?
This is a review of Statwing. Statwing is magic. You give it CSVs, and it imbues you with a godlike power to analyze data without really knowing statistics.
My main job involves hiring engineers for startups, but if you’re reading my blog, you probably know that a big part of what I do involves writing data-driven posts about trends in technical recruiting — Lessons from a year’s worth of hiring data and What I learned from reading 8,000 recruiting messages in particular. I’d like to pull back the curtain a bit to talk about a tool that has made creating content like this so much easier.
Way before I wrote my first post, I was a devoted admirer of OKTrends. That blog, to me, was the platonic ideal of good writing: actual data rather than conjecture, complex ideas made simple, unexpected insights into the human condition, interactive graphs, and dick jokes. It was perfect.
Then, a few years ago, when I finally had enough data to do something interesting, I ran across a rather upsetting Quora answer to How important was blogging to OkCupid’s success? Particularly distressing was this part:
The posts each took 4-8 weeks of full-time work for [Christian Rudder] to write. Plus another 2-4 weeks of dedicated programming time from someone else on the team. It’s easy to look at an OkTrends post, with all its simple graphs and casual writing style and think someone just threw it together, but it probably had 50 serious revisions.
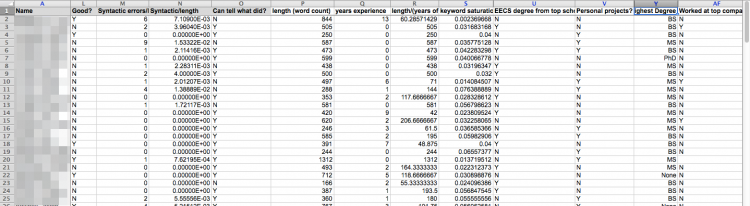
The project I was working on (later to become Lessons from a year’s worth of hiring data) was an attempt to figure out what attributes of engineers’ resumes mattered the most when it came to getting offers. Here’s a screenshot of what the raw data looked like:
At the time, drawing conclusions from this mass seemed somewhat intractable, and after reading the answer about OKTrends I was really quite discouraged. After all, the last time I had done any kind of meaningful stats work was in high school. I started brushing up on statistical significance, what kinds of data merited what kinds of significance tests, what p-values meant, and so on. In parallel, I started looking for a viable Excel plugin that would run these tests for me in a way that didn’t force me to do a lot of preprocessing and would give me outputs that I didn’t have to do additional work to make sense of. I also started working through a few R tutorials, hoping that doing things at the command prompt would be less painful than clicking around Excel plugins aimlessly. Limping through R filled me with a vague existential dread, so I stopped.
Then, I saw a post on Hacker News about something called Statwing that claimed to simplify statistical analysis. I took it for a spin, uploaded a CSV file like the one above, and saw that I could click on any 2 column names and ask Statwing to tell me if the relationship between them was significant. Statwing ended up being game-changing and made it possible for me to churn out content I was really proud of a lot faster — it’s probably not an exaggeration to say that Statwing saved me a few weeks’ worth of work for each post.
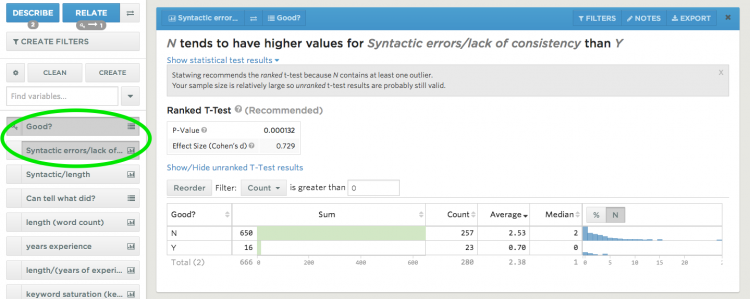
To get an idea of what it actually does, let’s say you have the spreadsheet above and want to figure out if having syntactic errors (typos, grammar, etc.) matters when it comes to getting an offer. To do that, all you have to do is click the 2 columns, like so:
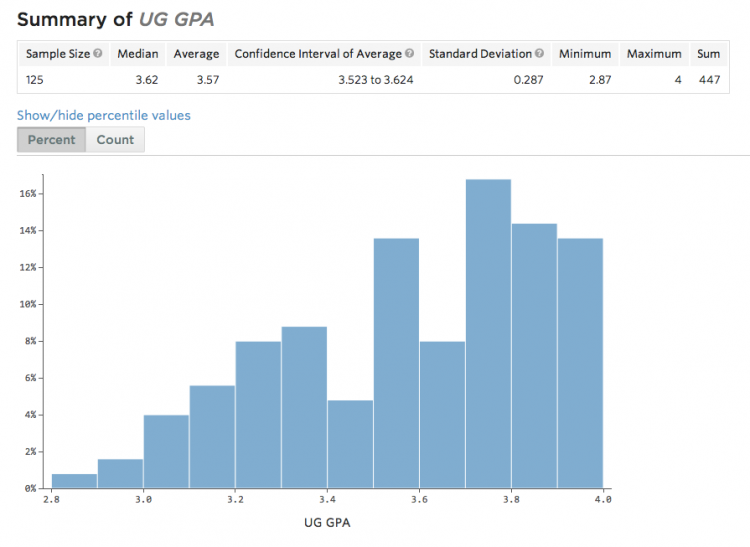
Statwing is also very, very good at classifying data into types (categorical, numerical, etc) and figuring out what tests are appropriate for that type, including noting when your data has outliers and modifying the statistical test accordingly (as you can see, above, Statwing chose a ranked t-test over an unranked one). It also provides the usual slew of descriptive statistics (means, std devs), lovely histograms, and so on. Below, you can see some descriptive stats and a histogram of everyone’s GPAs:
One of my favorite features is the filter that lets you analyze just a subset of your data. Here, you can see me trying to figure out if having an EECS degree from a top school matters specifically in candidates that come from top companies:
I now find myself relying on Statwing as a sort of exobrain wired for statistics — instead of having to agonize over which parts of the data I should analyze, I can do ALL THE ANALYSIS without tradeoffs, lowering the barrier to finding delightful and unexpected outcomes. In some sense, Statwing almost makes things too easy, and it’s important to remind yourself that statistical significance or a strong correlation do not necessarily make for insights and that there could always be selection biases, a third variable controlling everything behind the scenes, Simpson’s paradox, or some other beastie.
Statwing is still a young product, so there are certainly some things missing. Inside of Statwing, you’ll find all sorts of lovely interactive graphs. But, for now, you can’t embed them in places and have to make your own (protip: use Plotly). And, because a lot of the data I work with has boolean outcomes, I wish Statwing had support for logistic regressions (though I hear that this feature is currently in the works, so perhaps it’ll be a thing by the time you read this).
At the end of the day, while using Statwing won’t turn you into Christian Rudder, it can significantly reduce the amount of time it takes to run stats on your data and generally turn data analysis from something terrifying into a delightful, empowering experience. So, if you want to try your hand at doing some of your own OKTrends-style blogging, now you can, with less pain. Of course, figuring out what to write about, gathering the data, presenting it well, and, of course, making the requisite dick jokes is on you.
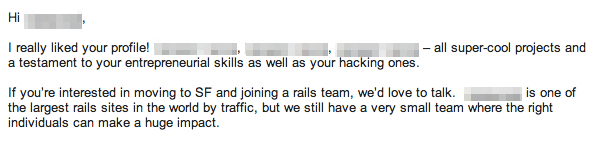
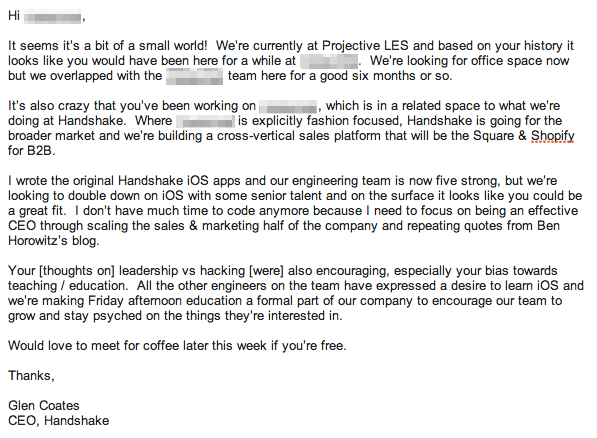
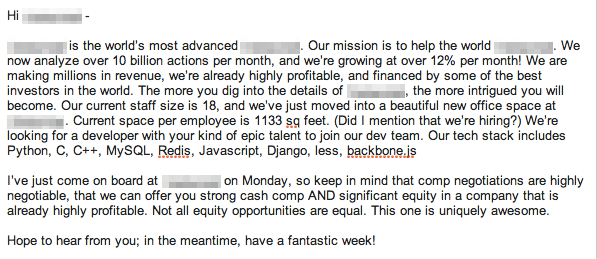
If you’ve ever been involved in hiring software engineers, you know how frustrating the process can be. One of the toughest parts is getting candidates’ attention. In an effort to understand what makes engineers respond to some recruiting messages and not others, I teamed up with the fine folks at Hired.
Hired is a 2-year-old marketplace where engineers create profiles, and companies bid on those engineers, auction-style. A personal message accompanies every bid a company makes on an engineer, providing a rich data set comprised of thousands of candidates, hundreds of companies, and thousands of messages between them.
We analyzed a sample of about 8,000 recruiting messages, examining a number of factors including company prestige and size, engineers’ desired salaries, degree of message personalization, and whether messages came from recruiters or from engineers/founders themselves. Our goal was to determine which factors would be predictive of an engineer deciding to engage with a company (referred to in this post from now on as the introduction rate).
In the process, we discovered that:
despite what people claim, money is hugely important in determining which opportunities to pursue
message personalization is very important, but not all personalization is created equal
left to their own devices, engineers and founders sound just as spammy as recruiters in their attempts to woo new talent
Here’s a graph of all the factors we looked at and their relative importance in predicting introduction rates. These values come from running a logistic regression on the factors that were most statistically significant. The y-axis represents the standardized value of the coefficients in our regression. It’s on a scale of -1 to 1 and represents how heavily each of these factors weighed into predicting whether a candidate was interested in an opportunity. Bars that are below the x axis mean that that factor has a negative effect. Note that all the graphs in this post are interactive, so you can hover and do other fun things.
Mobile users, please click here to view this graph.
These findings require a bit of explanation, so below, I’ve drilled down into a few of the more interesting takeaways.
Money
Although Hired’s data provides a pretty good approximation for email recruiting, recruiting messages in the wild don’t generally come with a numerical offer value. I was curious about how money might change the game, so in addition to examining what aspects of the messaging itself are sticky, we also looked at the effects of setting expectations around compensation up front.
Of all the different factors that went into whether a candidate was interested in a job, money was by far the most significant. This particular metric refers to offer (bid) amount divided by a given engineer’s self-reported preferred salary. In other words, the more an offer exceeds some target the engineer has set, the more likely it is that he will respond affirmatively.
How much more likely? Assuming a preferred salary of $120,000, there’s a 45% introduction rate for interview requests right at that amount. Dropping the offer down to $110,000 results in a 34% intro rate. Upping it to $130,000 shoots the intro rate up to 54%. In other words, for an engineer with a $120,000 preferred salary, paying $10k more leads to a 20% higher chance of introduction, whereas paying $10k less leads to a 25% lower chance. To put it another way, even dropping an offer by $10,000 can be significantly detrimental. It’s also interesting to note the inflection point that occurs in the introduction rate is right where the offer amount is equal to an engineer’s preferred salary.
Mobile users, please click here to view this graph.
Despite the strong evidence that money talks when an engineer decides whether or not to engage with a company, we did see an interesting disparity in what engineers reported as important to them versus how they actually behaved. As you can see below, lack of interest in the company’s value proposition was twice as common as any other reason for not engaging with a company, including insufficient compensation. Of course, stronger compensation may make a candidate reconsider a given company’s value, and a company with greater value may be less likely to offer under market, so the effects aren’t independent.
Mobile users, please click here to view this graph.
Money is a convenient attribute to cite as important because it’s so easy to measure, but I’d be very surprised if it’s telling as much of the story as it appears to. In other words, before racing to the conclusion that engineers are driven primarily by greed, I would like to posit another idea. Figuring out what people want in a job is hard, given just someone’s work history and self-summary. Even in a world where a recruiter has perfect information about a candidate’s professional desires, framing a prospective employer’s offering in a succinct way that resonates with a candidate is still really difficult. The fact that so few messages on the platform were truly personal is indicative of that (more on that below). Money is an objective metric that encapsulates not only the financial strength of the business behind the offer, but also how much they need your skills. I believe that if there were a way to quantify “how interesting the projects you’ll be working on are to you”, “how great the people you’re working with will be”, the impact someone can make, and so on, those numbers would easily be as significant as cash.
Personalization
I’m a recruiter, and the nature of the beast is that I somewhat regularly send out cold emails. I used to be an engineer, however, so I viscerally despise recruiter spam. To prevent cognitive dissonance from melting my brain, I wanted to understand how much personalization is enough. To test how much personalization mattered when it came to introduction rates, I broke up the messages into 3 categories.
1. Not personal at all.
This message could have gone to anyone on the platform who met the criteria for a given position and still would have made sense. Example:
2. Somewhat personal.
This message mentions something about you that’s easily identifiable and maybe ties it back to the company. Example:
and
3. Totally personal.
This message was clearly meant for you, you unique and beautiful snowflake. It might talk about your past work in depth or mention some projects that you would be interested in for very specific reasons or appeal to your specific sensibilities when talking about the company vision. We didn’t redact this particular sender’s info because this message is a shining beacon of all that is good and right in cold emails. Example:
Despite the title of this post, reading almost 8,000 messages and scoring them for how personal they were was clearly intractable. Instead I wrote a little script that hashed messages with an edit distance of less than 60 characters (effectively covering recipient and sender first & last names) to the same bucket and surfaced messages that varied by more than this threshold amount. Those messages I scored manually.
First, here’s the distribution of personalization across all messages (n=7818):
Mobile users, please click here to view this graph.
As you can see, the vast majority of messages were effectively form letters, and it was especially surprising how few genuinely personal messages there were (a whopping 60 out of 7818 or ~0.8%).
So how much did personalization matter? For context, the average introduction rate on the entire platform was about 49.6%. Here’s the breakdown of introduction rate by personalization level:
Mobile users, please click here to view this graph.
What really struck me here was that adding a little bit of personalization didn’t appear to matter at all;in fact, the introduction rates for both impersonal and somewhat personal messages were virtually identical. In other words, the time it takes to drop in the moral equivalent of “Ohai I see you went to Local Good College, well so did our founders, go Local College Sports Team!” or just casually mentioning a candidate’s past employer or projects should probably be spent on something else. On the other hand, truly personal messages had a 73% introduction rate on the platform.
Unfortunately, all told, there were only 60 truly personal messages, probably because taking the time to write something unique is really hard. If you’re not an engineer yourself, knowing what to say can also be really difficult. To that end, I broke up each personalization tier by whether it came from a recruiter or from an engineer/founder. Perhaps not entirely surprising is that more impersonal messages came from recruiters than from engineers and founders (per capita).
Mobile users, please click here to view this graph.
What was surprising is the sheer volume of form-letter like messages that DID come from engineers and founders. In fact, over 85% of the messages that engineers and founders sent out were form letters; this is especially surprising given that those groups are the ones who are often on the receiving end of this kind of barrage.
Based on these findings, it seems like if you know enough about the subject matter, putting in a bit of effort and making messages truly personal is probably worth it. This is quite hard to do in the real world, where info about a candidate can be scattered all over the internets, if it’s even there at all. On a platform like Hired, however, where the candidate goes out of their way to write up a self-summary, talk about their interests, provide a resume, and more often than not, a GitHub profile, and where most of the people doing the hiring are also the ones working on the product and are in a position to talk about projects in a meaningful way, going personal is very likely worth the mental effort.
Who the message comes from
Personalization notwithstanding, I was also curious about whether who the message came from (recruiter, engineer, or founder) mattered when it came to introduction rate. To control for personalization, I focused on just the impersonal messages (n=6827). The breakdown of introduction rates was surprising:
Recruiter: 53%
Founder: 49%
Engineer: 47%
In other words, recruiter introduction rates were statistically significantly different from the others, and recruiter messages did better than messages from both engineers and founders. I was quite surprised by these results, so I did some sleuthing. First, let’s talk a bit about in what situations recruiters are likely to be the ones sending messages.
As a company grows, founders are less likely to be the ones doing recruiting. Below, you can see what portion of messages came from recruiters as a function of funding stage:
Mobile users, please click here to view this graph.
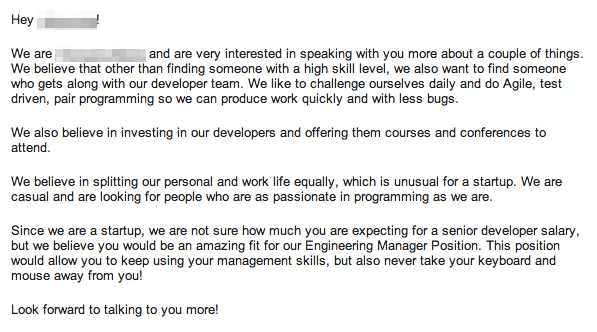
Saying that recruiters get more or less introductions overall isn’t truly meaningful because perhaps major corporations might have really strong brands, happen to have more recruiters doing messaging, and can potentially pay higher salaries. When I controlled for these things, the effect largely went away, and introduction rates were pretty much the same across the board, except for some outlier recruiter messaging. Here’s a good example.
What made messages like this particularly compelling was beyond me, but then I looked at non-recruiter messages in the same batch.
So what’s the difference? I think the secret sauce is in the tone. The recruiter message sounds genuinely excited and what it lacks in technical depth, it makes up for in enthusiasm.
The non-recruiter message, on the other hand, is a bit more dry, canned, and tentative. It also doesn’t do a good job of getting across the scope of the opportunity. Perhaps the takeaway here is that, if you can’t go personal, you should at least go enthusiastic — it may be in your best interest to hire good recruiters who know how to hit the right notes. While this kind of recruiting isn’t a substitute for genuinely engaging with your audience, having experience sending out tons of messages is going to make you better at it than someone who is uncomfortable with reaching out to strangers and hasn’t done enough of it to overcome their gag reflex.
Conclusion
So, at the end of the day, what is it that makes recruiting messages more sticky? What drives engineers to be interested in certain opportunities and not others? What can you do now to get better at attracting engineers to your company?
If you can, go deeply personal with your outbound recruiting messages. Talk about what you’re working on, how that ties into what the candidate has already done, and why what you’re doing matters to them. Name dropping and shallow, faux personalization attempts simply don’t cut it.
Reachouts from founders aren’t intrinsically more valuable, unless they’re personal and targeted.
Writing really good recruiting messages is hard, and when engineers and founders put on their recruiting hats, they don’t necessarily fare better than recruiters themselves. Good recruiters, on the other hand, are worth a lot. People who do it professionally are going to be able to craft more engaging messaging than those who don’t.
Trying to underpay good people isn’t going to make you any friends. And, being transparent about salaries out of the gate, assuming those salaries are competitive, may be a good strategy for standing out.
A huge thank you to Elliot Kulakow of Hired for all his help with the SCIENCE and the pretties. And finally, thanks to everyone who proofread this behemoth.
Recruiting great engineers is hard. You might guess that the hardest part is finding great people, but with the advent of LinkedIn, GitHub, and a number of search aggregators, it’s actually not too bad. The really hard part is finding great people who are likely to be interested in what you’re doing. To that end, wouldn’t it be great if you could reach out specifically to engineers who are already familiar with your product? It turns out that with a list of user emails and a few scripts, you can.
Companies with brands that are household names are doing this already — when they do cold reachouts, those reachouts are actually warm — chances are, anyone they contact will have used or heard of their product at some point. However, for companies who aren’t yet household names, cold reachouts are not that effective. Personalization of messages can help, sure, but execution can be difficult, either because the person writing the messages doesn’t have enough technical depth to do this right or because there’s not enough info available on the internets about the recipient to say anything meaningful.
So, how do you find engineers who are already familiar with your offering? All you need is a list of your users’ emails. If you don’t have that list, you’re probably doing it wrong. Also, if you’re a B2B company, you probably shouldn’t be poaching engineers from people who give you money, but I’ll leave questions of case-specific ethics as an exercise for the reader.
Once you have your user list, you can filter it to find the engineers by checking each email against GitHub to see if there’s a corresponding account. There are 2 ways to do this. One is free but is also information-poor, and slow. The other will cost you a few hundred bucks but will provide a lot more info about people and will be orders of magnitude faster. Choose your weapon.
To get all the code mentioned in this post, go to my GitHub.
Free but slow
One way to see if someone is an engineer is to ping GitHub directly. This is something you’re probably already doing anyway when you source, but doing it manually is slow and intractable on a large user list. Instead, here’s a Python script that pings GitHub to see if there are GitHub accounts associated with your users’ emails.
import json
import urllib
import urllib2
import base64
def call_github(email):
"""Calls GitHub with an email
Returns a user's GitHub URL, if one exists.
Otherwise returns None """
url = 'https://api.github.com/search/users'
values = {'q' : '{0} in:email type:user repos:>0'.format(email) }
# TODO insert your credentials here or read them from a config file or whatever
# First param is username, 2nd param is passwd
# Without credentials, you'll be limited to 5 requests per minute
auth_info = '{0}:{1}'.format('','')
basic = base64.b64encode(auth_info)
headers = { 'Authorization' : 'Basic ' + basic }
params = urllib.urlencode(values)
req = urllib2.Request('{0}?{1}'.format(url,params), headers=headers)
response = json.loads(urllib2.urlopen(req).read())
if response and response['total_count'] == 1:
return response['items'][0]['html_url']
else:
return None
I chose to only consider people who have at least one repo. You can be more liberal and look at everyone, but empirically profiles with 0 repos have been pretty useless. You can also filter further by limiting your search to people who have some number of followers, code in a certain language, etc. The full list of params is here. Note that although location is listed as a filter and can be good (i.e. if you can’t support remote workers and if it’s not H-1B season), the search is not as useful as it could be because location is a self-reported, optional field, and users who don’t specify location will not be included in the results.
One of the big downsides of this approach is contending with GitHub’s rate limit: 20 requests/min with credentials or 5 requests/min without. To put things in perspective, if you have 500,000 email addresses to go through, at 20 requests/minute, you’re looking at about 18 days for something like this to run. With that in mind, if you’re dealing with a long list of emails, you could potentially use a number of GitHub credentials and load balance requests across them. At the very least, I’d suggest spinning up an EC2 instance and running your script in a separate screen.
Not free but verbose and fast
Though the GitHub approach isn’t bad, it has 2 serious drawbacks. First, just a GitHub account may not be enough info about someone in and of itself. You’ll probably want to find the person’s LinkedIn to see where they work and how long they’ve been there, as well as their personal site/blog if one exists (and probably other stuff that comprises their web presence)1. Secondly, GitHub’s rate limit is pretty crippling, as you saw above.
If you don’t want to deal with either of these drawbacks and are down to shell out a bit of cash, Sourcing.io is pretty terrific. It’s a lightweight search aggregator that pulls in info about engineers from GitHub, Twitter, and a slew of other sources, provides merit scores based on GitHub activity and Twitter followings, and includes links to pretty much everything you’d want to know about a person inline (LinkedIn, Twitter, GitHub, personal website, etc). Unlike many of its competitors, it has supremely elegant UX and non-enterprise pricing. And, most importantly, it has a fantastic API that lets you search by email and, at least at the time of this posting, doesn’t have firm rate limits. As I mentioned, in addition to returning someone’s GitHub profile, the API will provide you with a bunch of other useful info if it exists. Here’s an example response to give you an idea of some of the fields that are available:
And here are teh codez for getting someone’s title, homepage, LinkedIn, GitHub, and Twitter from their email:
import json
import urllib2
def call_sourcingio(email):
"""Calls Sourcing.io with an email
Returns a user's title and relevant URLs, if any exist.
Otherwise returns None """
try:
url = 'https://api.sourcing.io/v1/people/email/{0}'
# TODO insert your API key here
key = ''
request = urllib2.Request(url.format(email))
request.add_header('Authorization', 'Bearer {0}'.format(key))
response_object = urllib2.urlopen(request)
response = json.loads(response_object.read())
except urllib2.HTTPError, err:
if err.code == 404:
return None
else:
raise err
return {
'headline': response['headline'], \
'linkedin': 'https://www.linkedin.com/{0}'.format(response['linkedin']), \
'github': 'https://github.com/{0}'.format(response['github']), \
'twitter': 'https://twitter.com/{0}'.format(response['twitter']), \
'url': response['url']
}
Going through your result set with less pain
Once you have your result set, you have to go through all your users’ GitHub accounts to figure out who’s worth contacting and what to say to them. In most cases, this result set will be pretty small because most of your users probably won’t be engineers, so going through it by hand isn’t the worst thing in the world. That said, there are still a few things you can do to make your life easier.
I ended up writing a script that iterated through every user who had a GitHub account and printed them to the terminal as it went. Each time a new user came up, my script would open a new browser tab with their GitHub account ready to go (and potentially other URLs). It would also copy the current user’s email address to the clipboard so that if I decided to contact them, I’d have one less thing to do. Note that to use Pyperclip (the thing that handles copying to the clipboard), you have to download it first.
import json
import webbrowser
import pyperclip
def parse_potential_engineers(results_filename):
"""Goes through potential engineers one by one"""
json_data = open(results_filename)
results = json.load(json_data)
json_data.close()
for email in results:
if results[email] == None:
continue
print email
print results[email]
webbrowser.open(results[email]['github']) # open GitHub page in a new browser window
pyperclip.copy(email) # copy email address to clipboard
sys.stdin.readline()
Don’t be awful
As a final word of caution, I’ll say this. If you’re the one using these scripts, you’re either an engineer or have been one at some point, and you know how shitty it is to be inundated with soulless recruiter spam. These tactics give you the opportunity to find out enough about the people you’ll be emailing to write something meaningful. Talk about their projects and how those projects relate to what your company is doing. Talk about why someone would want to work for your company beyond just stupid perks or how well-funded you are. And if you find engineers who have great blogs or GitHubs but no pedigree, give them a chance. In other words, please use your newfound powers for good.
EDIT: After some good discussion, I think it’s worth pointing out that while a GitHub account isn’t a bad signal for whether someone is an engineer, the absence of one most certainly is NOT a signal that someone is not an engineer, and it’s certainly not a signal that someone is not a great one. Several of the best engineers I know simply don’t have side projects or don’t throw their side projects’ source code out into the world or aren’t involved in the open source community. In other words, I would hate for someone to interpret this post as validation that a GitHub account is a good gating mechanism for job applicants.
1Tools like Rapportive and Connectifier can make your life easier when it comes to getting additional context about people, but Connectifier isn’t cheap, and Rapportive requires toggling Gmail. You can try using Rapportive programmatically — Jordan Wright did build a pretty great Python wrapper around Rapportive’s undocumented API, and I was trying to use it initially to get more info about users — but that thing gets throttled real fast-like.
Looking for a job yourself? Work with a recruiter who’s a former engineer and can actually understand what you’re looking for. Drop me a line at aline@alinelerner.com.
This is a review of Lever, my favorite applicant tracking system (ATS).
ATSs suck
There are a lot of bad ATSs out there. I’ve tried out most of them at this point, and I’m consistently shocked at how they manage to stay in business. Their ability to survive is a testament to how terrible the recruiting software space is. Hiring software is really hard to build correctly because as soon as you get some traction, your big-name enterprise customers start demanding one-off customizations in exchange for fat wads of cash, and that’s hard to say no to. But as soon as you go down the perilous rabbit hole of building custom features, you lose out on usability for the rest of your customer base. As a result, building software can easily devolve into a game of checking as many feature boxes as possible. This is especially true in enterprise sales because the person who ultimately makes the purchasing decisions isn’t necessarily the same person who actually uses the product in question. An extreme example of this is Taleo, which purports to do everything from sourcing and managing the interview pipeline to onboarding candidates and reviewing employees. On paper, it checks all the boxes. It’s the perfect system. But in reality, the product pretty much fails at everything. So then instead of getting a system that does everything, you end up with a hefty subscription fee for a system that actually does nothing useful at all. By the time you realize this, they have all your data. Migration is a nightmare, so you just grin and bear it because they have you by the balls.
It’s absurd how companies that are otherwise really good at things continue to give money to bloated, clunky, borderline unusable products like Taleo and Jobvite.
Lever is awesome
Lever isn’t like that. You know how sometimes you use a product and just feel really good because you can tell it was made by people who get it? It’s so rare, and it’s even rarer in B2B/enterprise software space. With Lever, it’s immediately clear that UX was a priority from day one and that the people who built it took the time to understand the recruiting space rather than just frankensteining together features that sound good on paper. Everything about the Lever experience is deliberate. The product is moving toward a vision of recruiting that I really love — there’s no process for the sake of process, just a system that unobtrusively gives you access to all the info you need and lets you intuitively collaborate with anyone on your team who’s involved in hiring.
Below is some stuff about Lever I really like.
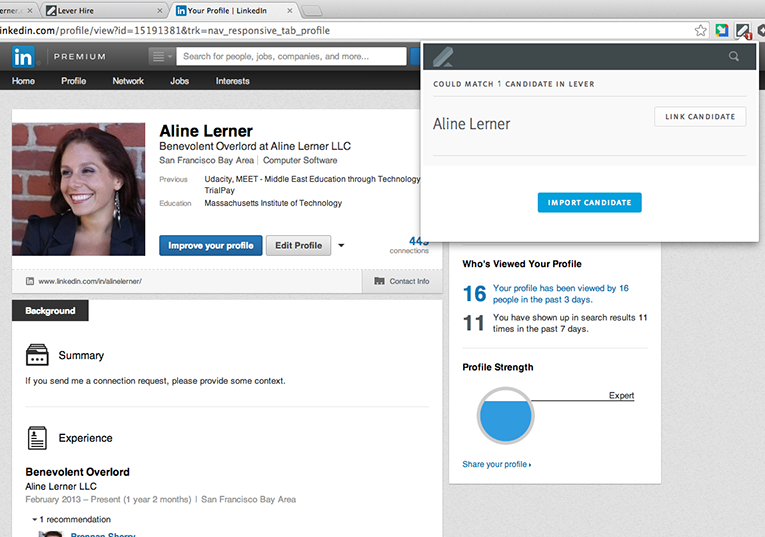
Amazing LinkedIn (and other site) integration
This feature is ridiculously useful. If you’re looking at someone’s LinkedIn profile, Lever’s browser extension can scrape the page and automatically create a corresponding entry in Lever. On top of that, if I’m looking at someone’s LinkedIn profile, and a candidate with the same name already exists in Lever, Lever alerts me and asks if they’re the same person.
This feature is fantastic for collaboration around sourcing, especially if a few people are sourcing within your organization. In the status quo, candidate information is probably going to be in some mix of different people’s emails, LinkedIn, StackOverflow, your current ATS, social media, and so on. This dispersal of information makes it difficult to effectively track who’s been reached out to. The low-friction candidate import features in Lever make it possible for all this info to live in one place, ultimately making it much easier to track response rates and prevent noob mistakes like contacting the same person multiple times without context.
In addition to LinkedIn, you can use the extension with pretty much any site (e.g. GitHub), though not all sites will have a preconfigured scraper.
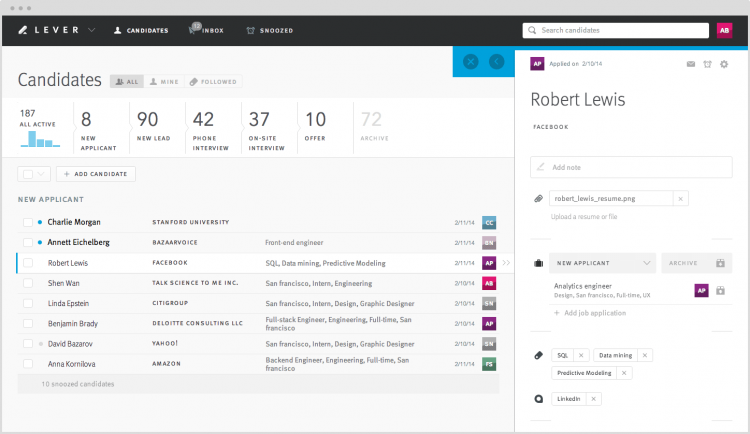
Snapshot of state
When you log in, you can see exactly who’s in what part of the pipeline.
When you drill down into an individual candidate, you can see everything that’s happened until now inline, including all candidate communication, as well as internal notes and interview feedback. Moreover, any activity that goes with a candidate is always associated with an actor and a timestamp so that you can begin to ask and answer questions about your actual internal process and how it’s going. You’d think this is a given, but I haven’t seen any other product nail this aspect.
It’s not gross to use for non-recruiters
If you want someone else on your team to do something related to a candidate, you just @ them, and the conversation ends up in email. This is particularly awesome because it’s intuitive for people on your team who aren’t recruiters. In general, the feel of the product is about fitting in with Google Apps rather than making you do things in a bunch of places.
The Lever experience also tries to mirror how people would actually operate during hiring if the hiring process weren’t muddled with, well, process. The notion of filling out forms to submit feedback is absent, and though you can customize your process in any way that you want, the idea that you have to rank candidates on some scale or fill in ten different form fields about candidates’ aptitude isn’t something that’s taken for granted. The product doesn’t make any assumptions. All it does is remove the friction associated with storing information and having a bunch of different people interact with it, whether they’re used to doing hiring-related stuff or not.
Ability to snooze candidates and delay rejection emails
Lever has a few Boomerang-like features I really like. Let’s say you reach out to someone over email, and they respond to tell you that they’re stuck at their current gig for the next 6 months. There are a number of home-grown ways to deal with this in the status quo, but none of them are centralized. Lever actually lets you “snooze” candidates for some amount of time and resurface them when it’s time to make contact again. You even get a calendar invite reminder.
Another great feature is rejection email delay. I hate looking at a candidate, deciding he’s not a fit, and then having to remember to reject him later because it’s kind of terrible to reject someone 5 minutes after they apply. To avoid this, Lever lets you schedule rejections for some time in the future.
Things I don’t like
Lever isn’t without shortcomings. The product is extremely young. Bugs crop up from time to time. And there are lots of features that are missing. Here are some shortcomings I noticed.
Absence of tracking on outbound emails and job postings
It would be cool if you could track when candidates open emails and track click-through rate on job postings.
Inconsistent candidate duplication detection
As I mentioned above, Lever’s LinkedIn browser extension is very good at catching candidates you’re looking at in LinkedIn who might also exist in Lever. Unfortunately, if you enter candidates in manually, and you already have someone in the system with the same name, there isn’t any warning asking you if this is intentional.
Somewhat clunky setup process
When you initially set up Lever, you have to talk with someone on the team to get it configured for your company’s pipeline/interview process. Though this isn’t unpleasant, ideally there’d be a way to self-serve any configuration stuff through an admin site.
Stop giving money to shitty products
At the end of the day, I’d caution users to not get into the trap of comparing a product to its platonic ideal over comparing a product to the status quo. In terms of what’s out there at the moment, and given how great Lever is already, I have no idea why everyone wouldn’t use it. Yeah, migration is kind of a bitch (though Lever does its best to make it less painful), and yeah, it’s kind of risky to depend on a very young company that might not be around in a few years, but I see moving away from a terrible ATS to Lever as not only as a rational decision but as a proud rejection of clunky, enterprise systems that make users miserable. Sunk costs, fear, and complacency are not good reasons to make decisions. Awesomeness is.