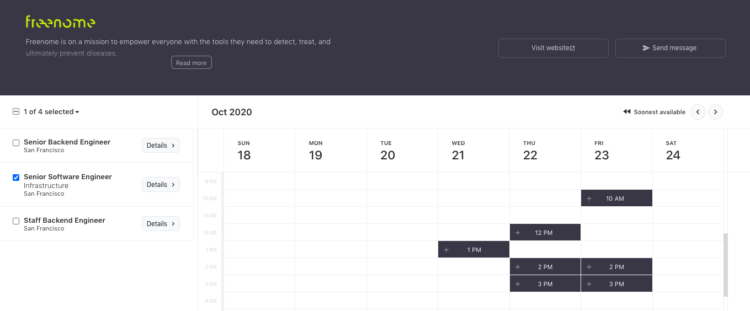
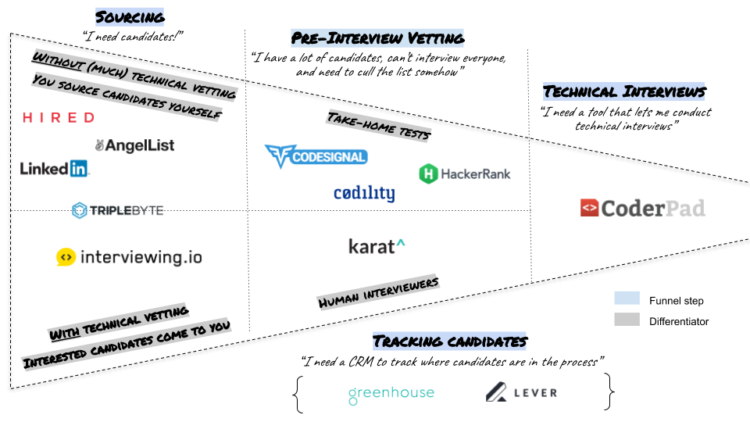
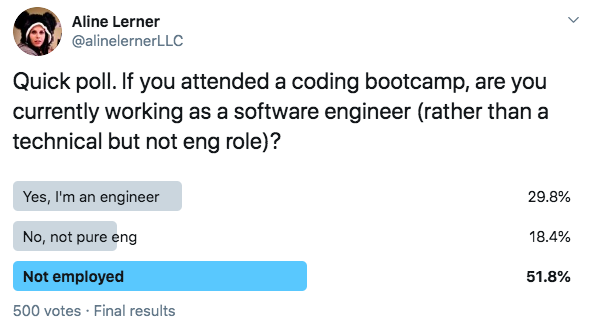
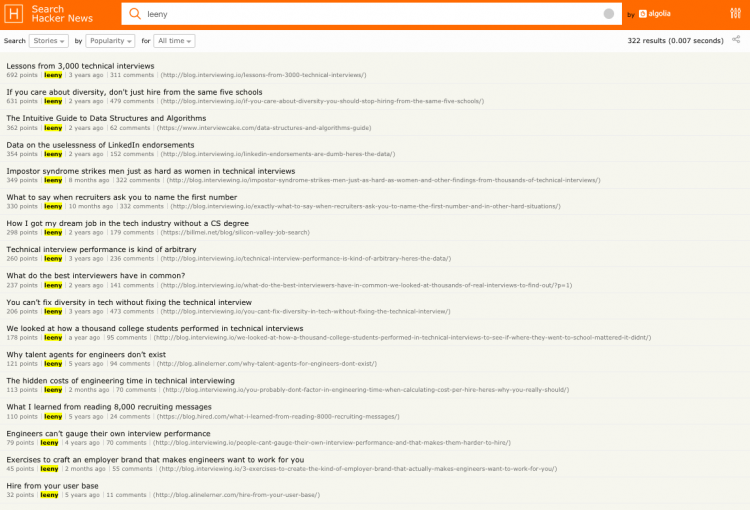
I’m the founder of a company called interviewing.io. We’re an anonymous mock interview platform and a technical recruiting marketplace — software engineers use us for interview practice, and we connect the best performers to top companies, regardless of how they look on paper.
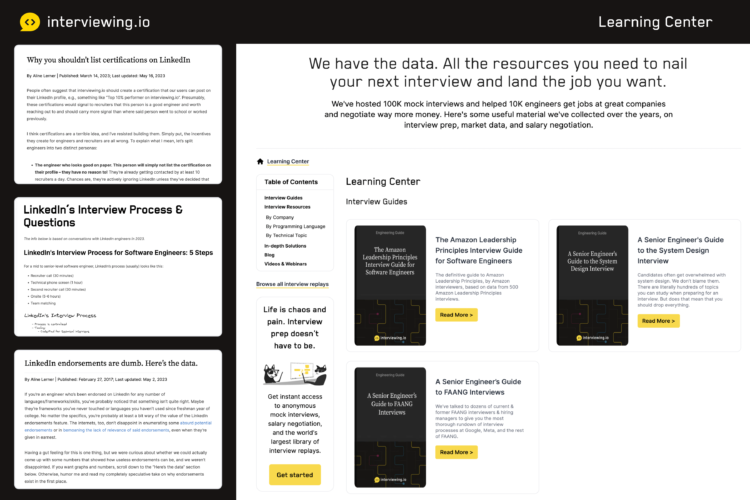
Content has always been a big part of who we are. We’ve hosted over 100k technical interviews in our lifetime, and we regularly use the data from those interviews and from our broader community, to tell stories and create interview prep resources. Recently, we published a big interview prep resource hub. After I posted about our new resource hub on LinkedIn, LinkedIn silently deleted my account and all of my company’s followers.
I suspect that one or more of the following happened:
- Someone at LinkedIn made a mistake that resulted in my account being banned (and likely permanently if I didn’t know someone).
- LinkedIn doesn’t know who their users are. That’s poor identity management, especially for a hiring platform.
- LinkedIn bans their competitors and then attempts to hide this under the guise of security practices.
I want to allow for the possibility that what happened to me was simply due to someone’s mistake. On the off chance that someone from LinkedIn does see this post and explains what happened, I commit to posting the response and, depending on what it is, completely retracting my theory.
However, if it’s either #2 or #3, it’s worth speaking out about. It’s not great that the leading hiring platform in the U.S. can’t verify the identities of its users. You can’t be good at hiring if you can’t vouch that the people showing up for the interview are the same people who applied. Given that I’m fairly well known in the recruiting space (and have been logging in from the same place for years), it’s bad if my identity can’t be verified. And if it’s not an issue of identity management but is indeed an attempt to silence other recruiting platforms, that’s definitely worth calling out.
I was ultimately able to get my account back because our investors connected me to a human at LinkedIn. But, if I hadn’t known someone, I’d probably never have gotten it back, so I want to share my story to 1) see if this has happened to anyone else (if it has, please email me: aline+linkedin@interviewing.io) and 2) maybe get some clarity from someone at LinkedIn, just in case I’m missing something — to this day, I haven’t been able to get a straight answer for what happened.
What happened?
On July 24, 2023, I published the following post on LinkedIn.
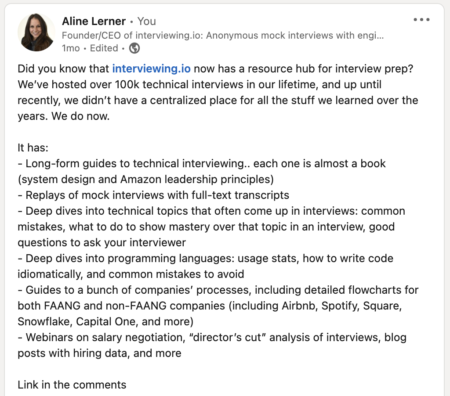
After I published, LinkedIn prompted me to turn it into a promoted post. I thought, “What the hell, why not?” and gave it a $500 budget.
Now, as you saw above, our resource hub does have some LinkedIn-related content. Some of it is neutral, and some is critical of LinkedIn. Neutral content includes detailed guides for how to prepare for interviews at Google, Meta, Amazon, and other companies (LinkedIn is one of them). We also have replays of technical interviews conducted by LinkedIn engineers that other engineers can watch and learn from.
Two blog posts contain content that’s critical of LinkedIn: one is called LinkedIn endorsements are dumb. Here’s the data. (What? They ARE dumb.) We also have one called Why you shouldn’t list certifications on LinkedIn (we stand by that one as well… certifications are also largely dumb).
The next morning, when I tried to log in to LinkedIn, I got hit with a screen that said that my account may have been compromised and that I need to submit a photo of a government ID to verify my identity. This seemed suspect, given that I hadn’t gotten any emails from LinkedIn about suspicious sign-ins (security table stakes these days). As such, I decided not to send photos of any of my IDs.
At the time, I didn’t quite put two and two together. I just assumed that I might be locked out of my account because of something to do with promoting my post. But I soon realized that there was more going on when I tried to search for myself.
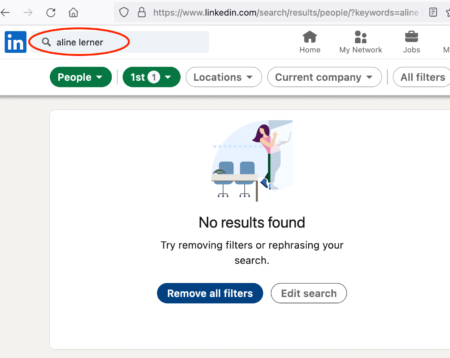
For a few days, my LinkedIn profile was gone from the internet, like I never existed
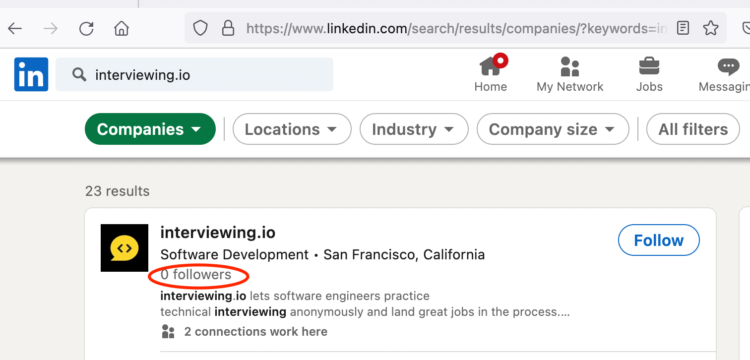
When I searched for myself on LinkedIn, this is what I saw. No results! Moreover, if you Googled me during this time and then clicked on the LinkedIn link, it would go to a dead page. Even stranger, my company suddenly had 0 followers.
Given that using LinkedIn is important for me to be able to do my job, I reached out to my network, asking if anyone knew a human at LinkedIn that I could talk to. I had tried to use LinkedIn’s support, but you need to be logged in, which resulted in a frustrating catch-22.
Within a day, I was emailing with a human at LinkedIn. She was a manager in a completely different department, but she escalated the issue, and two days after being deleted, I got an email from a case manager named “John” that my LinkedIn account was reinstated and had been removed in error.
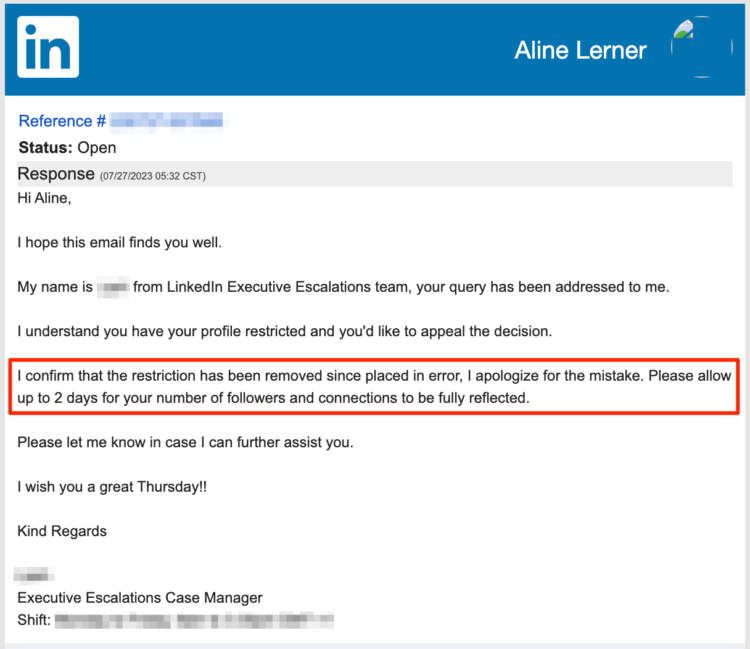
I tried to ask why I was deleted. Here’s what I learned.
If this were truly grounded in concern about the security of my account, why would my profile and all my content be gone? And why would my company suddenly have 0 followers? I asked “John” what happened and why.
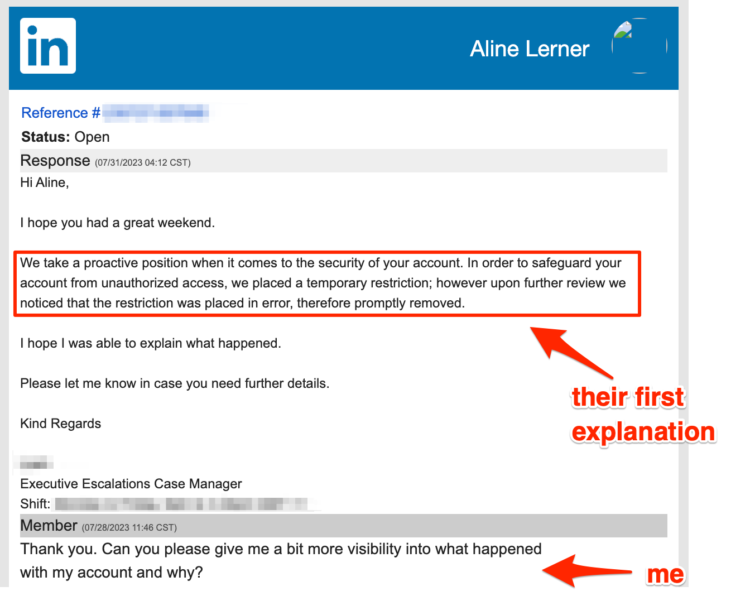
“John” reiterated the security rhetoric, as you can see above. So I pushed a bit harder. This time, I asked directly if it was about the content I posted. And it was!
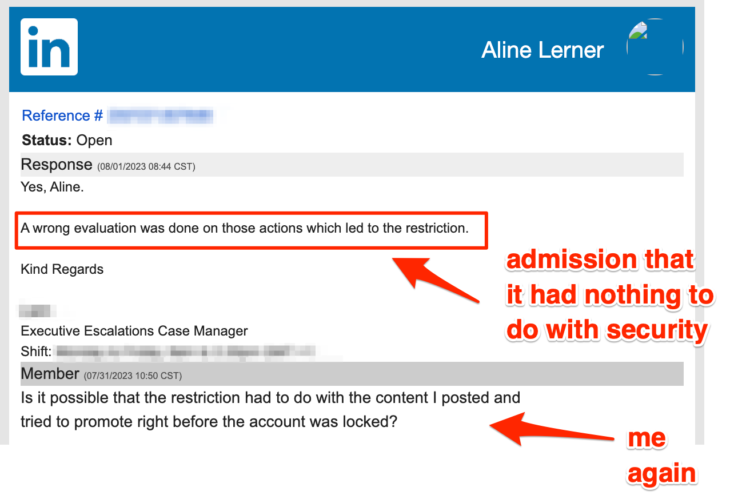
Now, I can hear the skeptics saying that the “wrong evaluation” was a security evaluation and that LinkedIn’s algorithms deduced that someone hacked my account and was promoting posts (because promoting posts isn’t something I usually do). Sure, I guess that’s possible. But it’s really unlikely — after all, if that were their model, they’d be shutting down every first-time purchaser of ads, which doesn’t seem like good business.
What I think happened
Before I get into what I think happened, I want to discuss another possibility. It’s time to invoke Occam’s more cynical cousin, Hanlon’s razor: Never attribute to malice that which is adequately explained by stupidity. Now, the people who work at LinkedIn certainly aren’t stupid, but I think it’s important to acknowledge that even the best-run companies make errors or have lame policies from time to time. I want to allow for the possibility that perhaps something silly happened or that my post flagged something that is completely unrelated to interviewing.io’s business and its content. Maybe someone just made a mistake.
But… even if it turns out that my account was removed due to a misunderstanding, it’s still worth speaking up about. Here’s why. A typical LinkedIn user without connections to people who work there could end up losing their account permanently and have no ability to resolve the issue. They would lose access to their professional network, would no longer be findable to recruiters, and would no longer have access to the millions of employers that post jobs on LinkedIn. That’s a considerable price to pay for someone else’s mistake. If that’s indeed what happened, I hope that LinkedIn will revisit their policies.
However, given that not only was my personal account removed but also my company’s account suddenly had zero followers, I can’t help thinking that this time something foul was afoot, something that couldn’t be handwaved away.
In a nutshell, I think that someone on LinkedIn’s ad team saw my attempt to promote the post, decided that the post was against their terms of service because it references content that derogated LinkedIn and/or shared stuff about LinkedIn’s hiring process that they didn’t want public, and proceeded to shadowban me because of it.
I took a close look at LinkedIn’s terms of service, and the only term that one could possibly accuse me of violating was the one below, because we used the word “LinkedIn” when talking about LinkedIn’s interview process as well as how useless LinkedIn endorsements and certifications are.
7. Violate the intellectual property or other rights of LinkedIn, including, without limitation, (i) copying or distributing our learning videos or other materials or (ii) copying or distributing our technology, unless it is released under open source licenses; (iii) using the word “LinkedIn” or our logos in any business name, email, or URL except as provided in the Brand Guidelines
That’s a stretch though, and it’s moot – LinkedIn must not think that I violated this term because they ended up walking back their decision to remove me.
Is it possible that LinkedIn can’t do identity management?
LinkedIn undoubtedly cares about security, but their seeming inability to identify who I am, despite me being a very vocal voice in the recruiting community and consistently logging in from the same IP address for years, speaks poorly of their identity management capability, which is kind of an important competency for a hiring platform. As the primary place where talent and employers connect, as well as a self-proclaimed up-skilling and learning platform, LinkedIn has some responsibility to be good at identity management and knowing who its users are. You can’t be a credible recruiting platform without this ability. (In the meantime, LinkedIn has no issue leaving up fake accounts that are being used for espionage.)
As it happens, we know a bit about identity management at interviewing.io — despite being an anonymous platform, we have a generally good handle on who our users are. We know how well people perform in interviews, we know how well they’re likely to perform in future interviews, and we certainly know if they are who they say they are and if their experience matches their resume. You know why we have to be good at this? Because we’re a platform that does hiring, and if we couldn’t do it, we’d be laughed out of the room. It’s implausible that LinkedIn, with all their resources and data, cannot figure out enough about their users to not demand government IDs (which they then proceed to ignore), especially when the user is a domain expert in their field.
How LinkedIn seems to do security
The fact that LinkedIn asked for my ID kept nagging at me, and I began to wonder if my situation was a common one. Fortuitously, a former interviewing.io employee also had his LinkedIn account deleted around the same time as mine. I first assumed it was because of our content. He, however, did blatantly violate LinkedIn’s terms — he changed his official name and heading to all emojis. Importantly, he experienced the same flow I did when he attempted to unlock his account. Unlike me, he complied. After LinkedIn got his ID, they informed him that he had violated their terms of service and removed him from the platform. That key detail helped me understand something about how LinkedIn does security.
So here’s what I know: users appear to get dumped into the security flow for a number of reasons (some of which may be completely orthogonal to the security of the account), and for some users (like my former employee), uploading a photo ID won’t solve it, even if the ID is legit. I don’t know if this is part of LinkedIn’s strategy or just a side effect of bad UX or bad customer service.
Regardless of whether it’s intentional or not, LinkedIn’s flow for any perceived violation of terms looks to be:
- Lock the user out of their account
- Remove the account such that it’s no longer visible on LinkedIn
- Tell the user that their account may have been compromised, and ask for photo ID
- Regardless of the outcome of (3), don’t undo anything and leave them locked out and deleted into perpetuity, without an explanation, UNLESS THEY KNOW SOMEONE
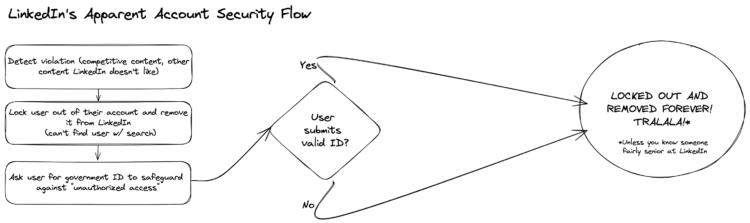
All in all, my experience begs the question: why is LinkedIn collecting IDs when 1) the issue isn’t a security threat but a terms violation and 2) they won’t reinstate your account whether or not you submit your ID? This all made me wonder if something more problematic was occurring, something that LinkedIn was hiding under their standardized security flow.
Anti-competitive practices masquerading as security is a dangerous pattern
Outside of the fact that I’m a paying LinkedIn user and that deleting your paying users without any explanation is kind of lame, it will be really lame if it turns out they’re trying to pass off anti-competitive behavior as a security measure.
There are a few things really wrong with the way LinkedIn seems to shadowban users. These are:
- Free speech
- Habeas corpus (that thing you where you can’t be held indefinitely without getting to face your accuser/a judge)
- Opportunity to know what wrongdoing you’ve been accused of
- Same treatment under the law regardless of social standing
Now, I can hear some of you grumbling, “Aline, habeas corpus? Come on!” I know, I know. But hang on a second. The value of these principles and how bad things get when they’re not part of a country’s guiding code and value system is something I know firsthand — I was born in the former Soviet Union. Having been on the other side, I find myself having an outsized response to violations of these principles.
Look, I know that LinkedIn is not a government institution, and as such, they are not bound to the Constitution and don’t have to operate like a court of law in the face of perceived wrongdoing by their users. This isn’t a post about how to apply the first amendment or any other amendment to corporate life. I especially know that the “free speech” argument is both nuanced and, honestly, a bit tired. Lots of people who are much smarter and better informed than I am who work in Trust & Safety at large social networks spend their careers debating what free speech means in the corporate realm.
Nevertheless, I have an especially strong immune reaction to violation of these principles in the service of silencing dissenting views, and, rather than engaging in transparent discourse, silently removing the problem as if it never existed.
It appears that LinkedIn is flagrantly silencing competitors, and rather than owning it, is masquerading their anticompetitive practices as security measures. We posted some true stuff about LinkedIn, my account was summarily removed, and my company’s followers dropped to zero. LinkedIn told me it was because there had possibly been unauthorized access to my account. If I had not found a way to talk to a human at LinkedIn, I likely would have been banned forever. That is not OK.
As such, I wrote this post to express my disappointment and to shine a light on something unethical. I’m trying to start a common-sense conversation that I hope LinkedIn’s leadership will see and, if something like this has happened to enough other people, will make them reevaluate their policies.
Now, you might argue that LinkedIn is just behaving like a normal business and that I’d do the same thing if I ran their company. Let me set the record straight. On interviewing.io, we’ve routinely hired (or offered to hire) for pretty much all of our competitors, including Indeed, LinkedIn, AngelList, Triplebyte, Hired, and others. We never messed with any companies’ rankings on our job board, never artificially put ourselves at the top, and never tried to get first dibs on the best engineers (behavior that multiple sources told me many recruiting companies engage in).
The one time we banned someone for competitive practices on interviewing.io was when the founder of a different mock interview platform joined our platform as an interviewer, and then during his interviews he tried to convince our users to switch over to his product. In that fairly egregious case, removing him from the platform seemed justified. However, we didn’t pretend to lock him out of his account because of “security measures.” We certainly didn’t ask for his government ID. We just stopped him from being able to use the product, and I told him why, directly. I don’t expect LinkedIn to call me up to explain, but I do expect them to operate by a professional code of ethics that prevents them from shadowbanning competitors.
I don’t want to win through cheating, and LinkedIn shouldn’t either. I want to win because we’ve empowered engineers to make informed decisions, and they chose us, fair and square. It’s a shame that the leading recruiting marketplace in the United States does not seem to operate under the same set of principles.
Has this ever happened to you?
I don’t think I’m alone in having my LinkedIn account shadowbanned because of something I posted. But I bet I’m one of the lucky few who was able to get back access to LinkedIn because I knew someone who knew someone. I expect most people won’t be that fortunate, so I want to help. We may not know the full picture until LinkedIn says something directly, but if enough people share their stories, we can begin to fill in the missing pieces of the puzzle.
Have you been removed by LinkedIn for something you posted? Get in touch by emailing aline+linkedin@interviewing.io. Though I’m not a journalist, I will abide by journalistic code, and if you tell me what you’re sharing is “off the record” 1) I will not reveal anything identifiable to anyone and 2) I will only use what you share in aggregate or as background information.