About a year ago, after looking at the resumes of engineers we had interviewed at TrialPay in 2012, I learned that the strongest signal for whether someone would get an offer was the number of typos and grammatical errors on their resume. On the other hand, where people went to school, their GPA, and highest degree earned didn’t matter at all. These results were pretty unexpected, ran counter to how resumes were normally filtered, and left me scratching my head about how good people are at making value judgments based on resumes, period. So, I decided to run an experiment.
In this experiment, I wanted to see how good engineers and recruiters were at resume-based candidate filtering. Going into it, I was pretty sure that engineers would do a much better job than recruiters. (They are technical! They don’t need to rely on proxies as much!) However, that’s not what happened at all. As it turned out, people were pretty bad at filtering resumes across the board, and after running the numbers, it began to look like resumes might not be a particularly effective filtering tool in the first place.
Setup
The setup was simple. I would:
- Take resumes from my collection.
- Remove all personally identifying info (name, contact info, dates, etc.).
- Show them to a bunch of recruiters and engineers.
- For each resume, ask just one question: Would you interview this candidate?
Essentially, each participant saw something like this:

If the participant didn’t want to interview the candidate, they’d have to write a few words about why. If they did want to interview, they also had the option of substantiating their decision, but, in the interest of not fatiguing participants, I didn’t require it.
To make judging easier, I told participants to pretend that they were hiring for a full-stack or back-end web dev role, as appropriate. I also told participants not to worry too much about the candidate’s seniority when making judgments and to assume that the seniority of the role matched the seniority of the candidate.
For each resume, I had a pretty good idea of how strong the engineer in question was, and I split resumes into two strength-based groups. To make this judgment call, I drew on my personal experience — most of the resumes came from candidates I placed (or tried to place) at top-tier startups. In these cases, I knew exactly how the engineer had done in technical interviews, and, more often than not, I had visibility into how they performed on the job afterwards. The remainder of resumes came from engineers I had worked with directly. The question was whether the participants in this experiment could figure out who was who just from the resume.
At this juncture, a disclaimer is in order. Certainly, someone’s subjective hirability based on the experience of one recruiter is not an oracle of engineering ability — with the advent of more data and more rigorous analysis, perhaps these results will be proven untrue. But, you gotta start somewhere. That said, here’s the experiment by the numbers.
- I used a total of 51 resumes in this study. 64% belonged to strong candidates.
- A total of 152 people participated in the experiment.
- Each participant made judgments on 6 randomly selected resumes from the original set of 51, for a total of 716 data points1.
If you want to take the experiment for a whirl yourself, you can do so here.
Participants were broken up into engineers (both engineers involved in hiring and hiring managers themselves) and recruiters (both in-house and agency). There were 46 recruiters (22 in-house and 24 agency) and 106 engineers (20 hiring managers and 86 non-manager engineers who were still involved in hiring).
Results
So, what ended up happening? Below, you can see a comparison of resume scores for both groups of candidates. A resume score is the average of all the votes each resume got, where a ‘no’ counted as 0 and a ‘yes’ vote counted as 1. The dotted line in each box is the mean for each resume group — you can see they’re pretty much the same. The solid line is the median, and the boxes contain the 2nd and 3rd quartiles on either side of it. As you can see, people weren’t very good at this task — what’s pretty alarming is that scores are all over the place, for both strong and less strong candidates.
Mobile users, please click here to view this graph.
Another way to look at the data is to look at the distribution of accuracy scores. Accuracy in this context refers to how many resumes people were able to tag correctly out of the subset of 6 that they saw. As you can see, results were all over the board.
Mobile users, please click here to view this graph.
On average, participants guessed correctly 53% of the time. This was pretty surprising, and at the risk of being glib, according to these results, when a good chunk of people involved in hiring make resume judgments, they might as well be flipping a coin.
Source: https://what-if.xkcd.com/19/
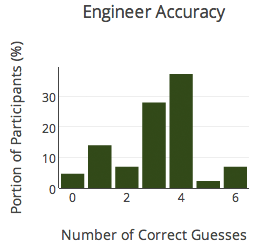
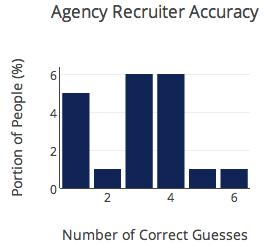
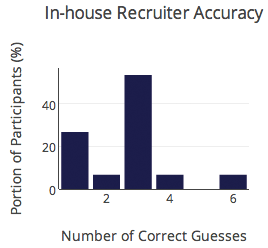
What about performance broken down by participant group? Here’s the breakdown:
- Agency recruiters – 56%
- Engineers – 54%
- In-house recruiters – 52%
- Eng hiring managers – 48%
None of the differences between participant groups were statistically significant. In other words, all groups did equally poorly. For each group, you can see how well people did below.

To try to understand whether people really were this bad at the task or whether perhaps the task itself was flawed, I ran some more stats. One thing I wanted to understand, in particular, was whether inter-rater agreement was high. In other words, when rating resumes, were participants disagreeing with each other more often than you’d expect to happen by chance? If so, then even if my criteria for whether each resume belonged to a strong candidate wasn’t perfect, the results would still be compelling — no matter how you slice it, if people involved in hiring consistently can’t come to a consensus, then something about the task at hand is too ambiguous.
The test I used to gauge inter-rater agreement is called Fleiss’ kappa. The result is on the following scale of -1 to 1:
- -1 perfect disagreement; no rater agrees with any other
- 0 random; the raters might as well have been flipping a coin
- 1 perfect agreement; the raters all agree with one another
Fleiss’ kappa for this data set was 0.13. 0.13 is close to zero, implying just mildly better than coin flip. In other words, the task of making value judgments based on these resumes was likely too ambiguous for humans to do well on with the given information alone.
TL;DR Resumes might actually suck.
Some interesting patterns
In addition to the finding out that people aren’t good at judging resumes, I was able to uncover a few interesting patterns.
Times didn’t matter
We’ve all heard of and were probably a bit incredulous about the study that showed recruiters spend less than 10 seconds on a resume on average. In this experiment, people took a lot longer to make value judgments. People took a median of 1 minute and 40 seconds per resume. In-house recruiters were fastest, and agency recruiters were slowest. However, how long someone spent looking at a resume appeared to have no bearing, overall, on whether they’d guess correctly.
Different things mattered to engineers and recruiters
Whenever a participant deemed a candidate not worth interviewing, they had to substantiate their decision. Though these criteria are clearly not the be-all and end-all of resume filtering — if they were, people would have done better — it was interesting to see that engineers and recruiters were looking for different things.2
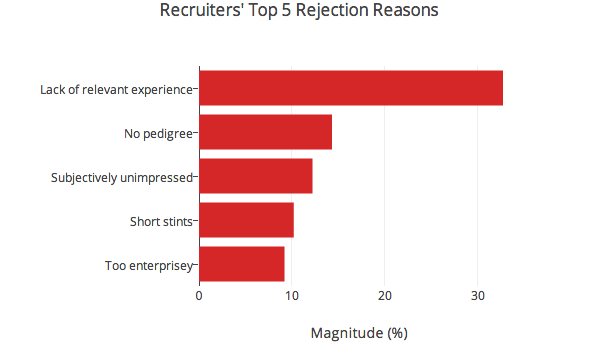
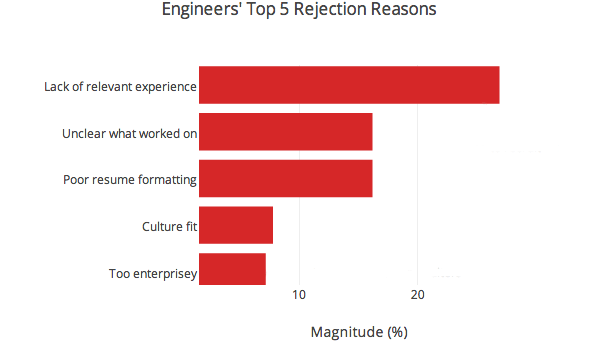
Incidentally, lack of relevant experience didn’t refer to lack of experience with a specific stack. Verbatim rejection reasons under this category tended to say stuff like “projects not extensive enough”, “lack of core computer science”, or “a lot of academic projects around EE, not a lot on the resume about programming or web development”. Culture fit in the engineering graph denotes concerns about engineering culture fit, rather than culture fit overall. This could be anything from concern that someone used to working with Microsoft technologies might not be at home in a RoR shop to worrying that the candidate is too much of a hacker to write clean, maintainable code.
Different groups did better on different kinds of resumes
First of all, and not surprisingly, engineers tended to do slightly better on resumes that had projects. Engineers also tended to do better on resumes that included detailed and clear explanations of what the candidate worked on. To get an idea of what I mean by detailed and clear explanations, take a look at the two versions below (source: Lessons from a year’s worth of hiring data). The first description can apply to pretty much any software engineering project, whereas after reading the second, you have a pretty good idea of what the candidate worked on.


Recruiters, on the other hand, tended to do better with candidates from top companies. This also makes sense. Agency recruiters deal with a huge, disparate candidate set while also dealing with a large number of companies in parallel. They’re going to have a lot of good breadth-first insight including which companies have the highest engineering bar, which companies recently had layoffs, which teams within a specific company are the strongest, and so on.
Resumes just aren’t that useful
So, why are people pretty bad at this task? As we saw above, it may not be a matter of being good or bad at judging resumes but rather a matter of the task itself being flawed — at the end of the day, the resume is a low-signal document.
If we’re honest, no one really knows how to write resumes particularly well. Many people get their first resume writing tips from their university’s career services department, which is staffed with people who’ve never held a job in the field they’re advising for. Shit, some of the most fervent resume advice I ever got was from a technical recruiter, who insisted that I list every technology I’d ever worked with on every single undergrad research project I’d ever done. I left his office in a cold sweaty panic, desperately trying to remember what version of Apache MIT had been running at the time.
Very smart people, who are otherwise fantastic writers, seem to check every ounce of intuition and personality at the door and churn out soulless documents expounding their experience with the software development life cycle or whatever… because they’re scared that sounding like a human being on their resume or not peppering it with enough keywords will eliminate them from the applicant pool before an engineer even has the chance to look at it.
Writing aside, reading resumes is a shitty and largely thankless task. If it’s not your job, it’s a distraction that you want to get over with so you can go back to writing code. And if it is your job, you probably have a huge stack to get through, so it’s going to be hard to do deep dives into people’s work and projects, even if you’re technical enough to understand them, provided they even include links to their work in the first place. On top of that, spending more time on a given resume may not even yield a more accurate result, at least according to what I observed in this study.
How to fix top-of-the-funnel filtering
Assuming that my results are reproducible and people, across the board, are really quite bad at filtering resumes, there are a few things we can do to make top-of-the-funnel filtering better. In the short term, improving collaboration across different teams involved in hiring is a good start. As we saw, engineers are better at judging certain kinds of resumes, and recruiters are better at others. If a resume has projects or a GitHub account with content listed, passing it over to an engineer to get a second opinion is probably a good idea. And if a candidate is coming from a company with a strong brand, but one that you’re not too familiar with, getting some insider info from a recruiter might not be the worst thing.
Longer-term, how engineers are filtered fundamentally needs to change. In my TrialPay study, I found that, in addition to grammatical errors, one of the things that mattered most was how clearly people described their work. In this study, I found that engineers were better at making judgments on resumes that included these kinds of descriptions. Given these findings, relying more heavily on a writing sample during the filtering process might be in order. For the writing sample, I am imagining something that isn’t a cover letter — people tend to make those pretty formulaic and don’t talk about anything too personal or interesting. Rather, it should be a concise description of something you worked on recently that you are excited to talk about, as explained to a non-technical audience. I think the non-technical audience aspect is critical because if you can break down complex concepts for a layman to understand, you’re probably a good communicator and actually understand what you worked on. Moreover, recruiters could actually read this description and make valuable judgments about whether the writing is good and whether they understand what the person did.
Honestly, I really hope that the resume dies a grisly death. One of the coolest things about coding is that it doesn’t take much time/effort to determine if someone can perform above some minimum threshold — all you need is the internets and a code editor. Of course, figuring out if someone is great is tough and takes more time, but figuring out if someone meets a minimum standard, mind you the same kind of minimum standard we’re trying to meet when we go through a pile of resumes, is pretty damn fast. And in light of this, relying on low-signal proxies doesn’t make sense at all.
Acknowledgements
A huge thank you to:
- All the engineers who let me use their resumes for this experiment
- Everyone who participated and took the time to judge resumes
- The fine people at Statwing and Plotly
- Stan Le for doing all the behind-the-scenes work that made running this experiment possible
- All the smart people who were kind enough to proofread this behemoth
1This number is less than 152*6=912 because not everyone who participated evaluated all 6 resumes.
2I created the categories below from participants’ full-text rejection reasons, after the fact.
This matches much of my experience, as an engineering lead, with trying to evaluate candidates. When I was working for a company, I had always received pre-filtered resumes, but even those were largely unreliable and I and soon started to feel that there was little connection between the quality of the resume and interview performance (say nothing about the quality of the interview and the on-job performance, that’s a different issue). I started to fear the high occurrence of false-positives in my process probably also came with an equally high occurrence of false-negatives. For every seemingly good candidate who turned out to be a bad employee, was I rejecting just as many seemingly bad candidates who would have been good employees?
Now that I’m freelancing and starting to build up a roster of other freelance developers with which I can collaborate, I don’t even bother with resumes anymore. I spend my time networking at developer meetups, getting to know people directly. If I think someone seems smart enough, and they talk about technologies suitable for my projects, I approach them directly about doing some part-time work with me. If I can get 10 hours a week out of someone on a regular basis, for the first month or so, that’s the real interview.
The traditional candidate search provides so low of a value that it does not justify the cost. I used to spend almost half of my time every week looking for good candidates and trying to figure out better ways to interview, and we were still getting bad employees out of it. So I figure, if we’re going to spend money on finding job candidates, let’s just spend the money on the job candidates. I can get back to work and maybe we’ll get some work out of the candidate in the process.
It’s slow, but I think the net “time-to-good-employee” is faster and costs less. It also feels like I’m not wasting the candidates’ time, because I get much more of a realistic work sample out of them than a take-home problem or a Github profile can provide, but they also get paid for the work they do. And being a part-time subcontractor, they’re pretty easy to let loose if they don’t meet expectations.
I agree with you on false-positives and false-negatives. I was worried more about the latter because the the former can be found out in due course and replaced but once I let slip a good guy, he/she might join a competitor which results in a double whammy for my company.
I also agree that getting a guy to work for a short span might be a good idea as it gives a better idea of how good he/she really is than a resume or an interview or a project report/work sample would provide. It also provides an opportunity to check if he/she fits in with the rest of the team and the organisation culture in general.
The only hassle is the time taken get a firm hire and many organisations are not looking at the -time-to-good-hire as the reality check that is needed.
I own a small company with technical employees (that have nothing to do with computer science) and have the same problem with resumes. I’ve discovered a few things: 1. How I evaluate a resume says more about me than the candidate. 2. One gross error goes to the bottom of the pile. Two or more and the candidate is eliminated. It sucks but there you have it. 3. I am looking more for evidence of cultural for than anything else. Do I want to have this person in my business every day? Regardless of pure talent can they be molded into a good communicator, team player, talented employee? Or will they be. Drag on the company? 4. My recruiter is expensive but totally fucking worth it. I review ten resumes and hire four of those candidates. Without my recruiter who has industry-specific and local knowledge way above par, I’d probably waste time liking at a hundred resumes and want to stab out my eyes.
BTW, I found a dumb error in my resume once. *After* I had read and revised it several times, *after* several competent friends had read it, and *after* a recruiter had read it before submitting it for a job. Note that the recruiter was likely very experienced in resumes, and would only get paid if I were hired.
To me, that says that an error in a resume says diddly all. The question is how gross it was.
2. One gross error goes to the bottom of the pile. Two or more and the candidate is eliminated. It sucks but there you have it
what do you consider a gross error?
Does using the word liking instead of looking count? lol
I was a bit surprised there was no analysis of if individual scorers were very good at determining quality. It could well be the case that agreement among many different people is the *last* thing you want. Instead, you may need to find the right screener to fill the job. At any rate, poor study design is probably the real reason there were random results. I understand its a bit of fun rigor on an informal study, but when not even you know what it is you’re measuring it’s hard to draw conclusions about the test subjects. Perhaps next time youcould take an objective, measurable candidate quality – how long they wound up working for the company, their salary, etc. – and ask people to estimate that instead. “Good fit” is vague and so you got vague results.
This is exactly why we build predictive models off of the digital interview and not the resume :). Nobody has ever made a hiring decision based on just the resume, that would be reckless, but as you point out using the resume to screen people offers little value in some cases.
Your conclusion is one of the main drivers behind ROIKOI. We’re building low-friction ways to do peer-to-peer professional reviews to solve the problem of quickly identifying really good people. Currently, we do this through an anonymous matchup game between highly relevant people and through mini-recommendations.
I’d be really interested in hearing your feedback on ROIKOI (are we even solving the right problems?) and how we can make identifying and hiring great people easier and faster.
Hey, happy to chat. Emailing you now!
This is one of the most useless comments one can leave.
There’s a reason you felt incredulous about The Ladders’ resume study — because it’s probably nonsense: https://resumegenius.com/5-problems-with-the-ladders-6-second-resume-study
You, on the other hand, have done an excellent and rigorous analysis. This is some valuable information you’ve uncovered — thanks for doing the hard work.
Notice how engineers don’t care about pedigree, LOL. I’d rather work with an incredible person without a degree than any smug snob douche from a big school any day of the week.
What would have been more interesting would have been to correlate the perception of the CV with the perception of the candidate after an interview. Controlling for difference in perception for when you know which CV belongs to who and blind interviews.
I would love to know if it even makes sense to review CVs or if another approach, like speed dating, wouldn’t be better altogether.
I’m confused as to how you categorized the candidates. You’ve got some that you defined as ‘strong’ – are these candidates that you’re hired, or your friends / colleagues who you rate highly? You’ve got candidates rated ‘less strong’ – says who? How much ‘less strong’? Are these the candidates you *didn’t* hire, in which case you’re basing your outcomes on the quality of the interview process.
Realistically resumes suck just as much as phone screens, interviews, tests, and working. It takes a long time to evaluate a candidate and even then there are more variables that can be accurately measured. We each have our own strengths and weaknesses.
As a senior software developer who has helped in a lot of interviews, I completely agree with your assessment about “resumes that included detailed and clear explanations of what the candidate worked on”.
When going through the big stack that is the first thing I look for. If they don’t list any projects, or if the projects they list are neither clear nor detailed, they go to the bin. If they do include details about what they did, and those details are clearly explained and seem like solid solutions, then I put them in the interview stack.
The other thing I look for is dropping names of specific events and websites. Someone who likes the field may go to school, participate, and earn a paycheck. They are likely so-so. But someone who is passionate will engage in challenges related to the topic, write blogs on the topic, and contribute to the community. It is okay to have people who show up and work, it is better to have people who are passionate.
During interviews they must also show passion. I don’t care if they show passion about their personal project, or show passion about why row major is better than column major ordering, or passion about all the frustrations they had using Oracle. I want to see that the candidate actually has deep feelings about the work they do.
I think this is mostly because many good people don’t know how to good write resumes and many bad people do know how to write good resumes. A guy who looks fantastic on paper may turn out to be a schlub, and another one with a horrible resume who only got brought in by reference turned out to be fantastic. If they were all written to a similar high standard I think your engineers would be pretty good at picking good candidates.
Definitely agree about typos and errors, and that candidates with ‘[I] did X’ tend to be much better than those who use the passive voice.
I’m always interested in hiring better so I’m very interested in this article. I took the sample test to get a feel for the data. One concern that I have is that different people and companies have different needs. Someone that is effective in my current employer would almost certainly be ineffective at my previous employer. Its hard to estimate how much variability can be attributed to different employers having different needs.
Another concern is this was a test to determine strong from not-as-strong. But is that the real goal of the resume? I expect the resume to serve as a rejection filter for people who are clearly not going to work.
I agree that resumes are a vastly inferior method of determining technical competence to actual testing. Automated coding tests make a wonderful addition to a hiring process. But I still find that my impression of the resume corresponds well to hiring outcomes.
Can you run the experiment again and tell the raters that they cannot reject a resume on any ‘lack of relevant experience’ grounds what soever? It would be curious if this ‘improved’ their ‘guessing’ or not.
You make a very good point, Karl. However, I wish to disagree with you and offer this:
As a software developer (over many decades) I need to be evaluated and ultimately hired based on my ability to write software; not my ability to write a good resume.
That is why several years ago I abandoned the “Traditional” resume and created A Github Repository as my [pseudo-]CV.
Admittedly, it has stymied many recruiters and “HR” experts. But anyone who would be my manager or supervisor – and has any technical experience – would recognize the format and find it more ‘comfortable’ to navigate.
I appreciate the careful and thorough testing done in this piece — it’s rare to see this sort of analysis applied to the hiring process for software engineers. However, I must respectfully disagree with your conclusion that the resume is the problem. I think an alternative and reasonable conclusion is that the most people (esp. engineers who are not hiring managers) are never taught how to properly evaluate a resume, or more critically, how to conduct an interview _using_ the resume.
An interesting follow up to this experiment might be to take a subset of engineers and teach them how to conduct a standardized interview using the resume as a guideline and compare the results against a control group who has no specific training.
I believe it’s much simpler to teach people how to do a good job of vetting candidates than it is to ask everyone in world to find a new format/tool to convey their work history.
My unsolicited $0.02. 🙂
> *all you need is the internets and a code editor*
> *but figuring out if someone meets a minimum standard*
Care to elaborate? For example, are you suggesting if I’m hiring a python dev, all I need to do is look a few lines of code and voila they make it past the “resume stage”?
I meant that you can make more accurate value judgments about people’s coding ability if you run them through some coding questions.
Resumes suck because they can. They’re not how engineers get jobs. I don’t know any software engineer today who is currently employed because of a resume. Do you think Guido sent a resume to Dropbox and they agreed to interview him because he spelled “Python” correctly, and formatted his resume nicely?
Job postings suck. Nobody likes them. They’re what you do when your entire company has run out of good friends (and friends-of-friends) they can hire. And sending resumes to job postings is what engineers do when they’ve run out of friends (and friends-of-friends) to hit up for jobs. They are each others yin and yang.
We’ve gone through phases where “open source is the new resume” or “Github is the new resume” or “blogs are the new resume” and each of these has a hint of truth to it. But the core truth they’re all getting at is that resumes are no longer what people use to get hired.
People are universally bad at filtering resumes because they don’t care. You don’t find a great programmer in a pile of resumes. Saying yes just means you’ll have to waste more time interviewing someone, and (best case) end up with 5 people sitting around a table saying “maybe…”
“I also told participants not to worry too much about the candidate’s seniority when making judgments and to assume that the seniority of the role matched the seniority of the candidate” At least for me, that’s one of the main reasons I read them. To make sure a candidate has the seniority we expect. If yes, then a follow up call can tell you more about his personality, experience and so on.
I’m quite new to hiring so I might be very naive, but for me at least is the main functionality of a CV!
The CVs in the experiment have the right hand side cut off, which makes the task difficult. They can be viewed in full by right clicking and viewing the image separately, but only the engineers are likely to realize this.
Also, I would be very curious to see how accurate the first cv is against the last. I paid a lot more attention to the first one, and as I am not going to be effected by these pseudo hiring decisions I suspect that fatigue sets in very quickly.
So people saw a random set of 6 resumes with the hope that the randomness would correct for the fatigue issue. Re the cutting off, thanks for reporting that! What browser/screen res are you using?
I had the same issue with the page being cut off (and the same solution of opening the image, or on one case, the set of three images, in another browser window). The issue was not resolved by changing my browser resolution. I’m using Firefox 28.0
I started to take the little test to see if I was any good at evaluating engineering resumes. And to my incredible shock and surprise, I 100% knew the first engineering resume. How in the world did you get his resume? Have you worked with him before? I worked with him at General Dynamics and helped him get his job at KForce. 🙂
I hired him at Udacity 🙂
My own experience has been that while the resume may make for high-level filtering (.net coder versus Java, etc.) it cannot be used for filtering out talent. We always run a technical screen on every candidate (like the speed dating suggested above). With a simple 30 minute pre-interview we get a very high correlation between candidates submitted and quality results for clients.
Hi,
As an engineer spending a lot of time seeing candidates in interview processes, I find this study quite interesting, but not surprising.
I think our job have something quite unique which is both a blessing and a curse:
– our educational system (at least in France where I am, I can’t be as affirmative for other countries) is flawed. I mean that people can get a degree even if they’re terrible at writing code or understanding specifications. So you can’t trust that.
– there are great online resources and open material to learn the job. Means that people without formal education can be wonderful engineers.
– problem solving and learning speed are as important as currently held knowledge. I’d even say more important. Those are difficult skills to assess. Experience is interesting, but sometimes it’s better to have someone with little to no experience but greater ability to adapt.
That’s a curse because recruiting is hard, that’s a blessing because chances are given to anyone.
For me, resumes don’t carry any of that information. I mostly use them to check if candidates explicitly mention some relevant experience or side-projects, thus I tend to approve a lot of them.
I’ve experimented with some filtering multiple-choice type tests, but I haven’t at the moment found a set of questions that makes a really good filter.
I’m about to suggest to my HR department a solution based on coding exams (in the form of mini case-study) that the candidates can take remotely with a time limit. Maybe that can give clearer insight about what a candidate can do: how she understands requirements, how she picks up a solution, and how she implements it.
Anyway, nice write up.
(I tried the study and also encountered the resumes being cut off and needed to open them as separate images. Latest firefox on windows 8, 1600*900 screen resolution)
What’s Too Enterprisey mean?
These were concerns about people having spent a long time (typically >5 years, iirc) at very large companies (Cisco, Oracle, etc). The fear there (not saying I agree necessarily) is that people who’ve worked there for extended periods of time might not be able to be productive in a much less structured environment, without the same tools, etc.
Oh thank god. I was afraid there was some new bias against us Star Trek fans.
HAH.
Same here – had to adjust my Chrome zoom level (1366×768 res) to show entire CVs in most cases. Also the trial banner at the bottom of the screen cut off the next (>>) button, so I had to inspect and delete it.
On another note, all 6 CVs I got were exceptionally good. I’d interview all of them. Maybe the midwest USA (where I work) has a severe lack of qualified candidates, so I’m just biased. Or maybe you just get really good CVs. Either way I’d love to know why I feel such a disparity here!
The test removes all personally identifiable information. I understand you’re trying to be objective, but what kind of test is it, then? I don’t have such generic hobbies as “photography” and “pizza”. If you removed all the PII from my resume, it would be a piece of junk. If you didn’t, I’d be easily recognizable to most techies in my city.
To use the Guido example: if it said “Designed and implemented one of the 10 most popular programming languages in the world”, could you rephrase that in a way that we didn’t know it was Guido’s resume? Or would you remove it entirely, thus negating the single most interesting fact on the page?
Here I see a “software guy” who is interested in “artificial intelligence” … I’m not sure if this is a boring resume, or a real resume that was made boring for the experiment. (Ooh, he dislikes GWT, how rebellious!) I’m not at all surprised that your experimental results are about the same as flipping a coin, because there’s nothing left here which would convince me of a solid yes or no. If I were forced to make a boolean decision, I probably *would* flip a coin!
The only reason I wouldn’t say No to all such dull resumes is that after 10 No’s in a row, HR would come into my office and yell at me again. HR (at any company big enough to have that as a dedicated position) seems to care more about headcount than anything else. Software engineering as a discipline is just starting to learn that lines-of-code have a cost, and you shouldn’t increase this number without reason, and you definitely shouldn’t measure progress by it, but HR doesn’t seem to have figured this out about headcount yet.
I bet if you added the option for “Maybe” (where it was understood that Maybe meant No, because you should never hire a Maybe) you’d suddenly get 90% Maybes. And if “I think I know this person” was not an exclusive option, that most Yes’s/No’s occurred when the reviewer said they know the person.
Good question. I didn’t edit people’s self-summaries — that stuff is an important cue, as you say. I did remove names, emails, phone #s, links (personal website, etc), and so on.
Great experiment and much appreciated. I just took your test. Would love to know how I fared if possible. Unfortunately, there was no indication of that at the end of the test.
@nickmg2020 so the test is truly anonymous, so i can’t pull your results, but if you remember specific wording you used, i could pull your score that way. or you could take it again and email me right after so i can find your entry based on timestamp. aline@alinelerner.com
At LifeGuides we’re scoring candidates based on how much content they consumer on a given topic. We’ve found that users who do the work are better qualified vs the traditional resume spammer.
Got news for you recruiters… pedigree means NOTHING. I am a founding team member of Amazon, a speaker at this years SpringOne conference and have spoken to developers at Mashery, Change.org , Paypal and others and worked at Microsoft, Apple, Cisco, Univ of Berkeley, Nike and many others. I am the creator of API Chaining, API Abstraction and many other concepts and I continue to innovate and improve.
The piece of paper means a person learned what pioneers like myself have forged when there was no one to teach it. That piece of paper is actually worthless when people get out into the workplace as they are actually 5 years behind still and those of us who are pioneering and even further ahead than that.
People in the trenches are cutting edge all the time so don’t limit yourself by turning a blind eye to those who don’t limit themselves
Yeah, I also thought that was ridiculous. I think it has something to do with the Boomer mentality. Something else they had mentioned was “too enterprising”, which goes well with the “No pedigree” character. They are basically looking for people who do what they are told and worked hard at hard universities. I guess they are worried about job hoppers who may even become a competitor.
I don’t know who said that resumes had to be a list of everything I’ve ever done, loaded with bullet points, created in MS Word, etc. That’s what they taught me in college (where 90% of my CS classes were irrelevant in the real world). This is how consulting companies doctor up your resume. I don’t get it at all.
The whole point of a resume is to sell yourself. When a company wants to sell me their services or products, they give me a piece of paper that is colorful, relevant, and easy to read… marketing material. Why don’t we write our resumes like that? What if I just come up with 2 pages of the most important stuff that I want people to know about. They don’t need to know every single thing I’ve ever done at work. When I interview with them, they can ask me about that if they want. But as someone who reads a lot of resumes, someone please write a resume that I want to read.
http://jonkruger.com/blog/2012/03/26/my-new-marketing-material-er-resume/
This sounds like a bizarre critique. A resume tells you whether a candidate has the right seniority, and the right skills/orientation. Of course it won’t tell you whether the candidate is brilliant or not (what did you expect?). However it also gives a lot of conversation fodder for an interview; and, besides, it also makes it much easier to communicate information about the candidate’s experience than if they had to make an entire oral presentation out of it (which is a skill quite unrelated to the technical and social skills usually expected of engineer recruits).
There is indeed little reason to reject a resume, unless the skills or seniority don’t fit with the position. Any other piece of information should be derived from a phone call or interview, IMO.
As for judging people on their writing skills… well, that’s a good way to eliminate people who are not native English speakers.
Tech resume writing largely varies from standard resume writing, requiring more complex terminology, while also needing to make sense to HR staff, and also impress technically minded IT managers.
http://resumewriterdirect.com/blogs/resume-and-career-advice/18693995-it-resume-writing-services-top-writing-tips
Too much of this is reliant on author’s perception of employee’s performance.
Hey, author here. I agree that I am not the source of truth for aptitude, and I do not want to live in a world where I am. The *really* interesting thing here, though, is that people all disagreed with each other, regardless of what I thought.
So..The research and comments point out that Resumes are boring and mostly useless for finding skilled candidates. It also shows that Coders, Project Managers and Recruiters are terrible at finding good candidates. Good. We should all avoid using these useless approaches.
Maybe one reason why these approaches fail is that they have NOTHING to do with what ACTUALLY goes on during the work day. Writing a good resume is COMPLETELY unrelated to coding, and to working on a project.
SO…What options are there which ACTUALLY RELATE TO THE WORK?
How about coming up with some basic skills and challenges from ACTUAL code that people at work are doing?
How about trying to have a conversation during a phone screen on how to solve common work type code challenges during the interview?
In other words, how about testing people by having them do things that ARE ACTUALLY PART OF THE JOB?
I just stumbled across this post. For the past year, I’ve been researching hiring bias, and I have bad news for you. Your “anonymized” resumes are anything but. They still reveal a number of bias-triggering elements:
* Name of university triggers confirmation bias. For example, many employers have a positive bias toward elite university degrees, while yep-yep-yep’s reply above reveals his disdain for those who come from that advantaged environment.
* Employer names: Same bias as with universities
* Tenure at each job, and job sequence. This much info constitutes a relatively unique pattern that might well identify someone
As many have commented, the only legitimate screening method is evaluating a concrete demonstration of capability and interest. Research shows that high predictive correlation is only available from a combination of two factors: raw mental ability and work samples (combined .63). Since the former is difficult to assess in an inexpensive, convenient, practical way, that leaves you with work samples. Source.
Go to varsidee.com to try a tool we’ve built that lets you publish a Tryout (our term for a work sample), where candidates submit concrete responses to your Tryout completely anonymously. You can include tests of hard skills, soft skills, culture factors, whatever’s important to you. Bonus: There’s a built-in communication feed that keeps candidates and your hiring team informed of all progress, which produces a much more brand-reinforcing candidate experience.
Ignore the Pricing page. Yesterday we decided to make the Tryouts free; we’ll change the page as quickly as we can.
Once you’ve screened in the good and screened out the poseurs, you can make use of Aline’s interviewing wizardry.
Hi Mike!
You claim your test is unbiased but how can it be if it is still reviewed by the hiring manager?
Best
Benjamin
Hi, Benjamin. Fair question. Thanks for asking.
The candidate’s work-sample submission is completely anonymous, identified only by a number, so the hiring manager evaluates that “can-do” evidence without knowing anything about the candidate. Only after the hiring manager determines that Candidate 123456 can do the job, and she takes a concrete step to advance the candidacy, e.g., request a phone screen or interview with 123456, does she see the candidate’s identity.
If the candidate isn’t clear about the Tryout instructions, he can use the Clarification function to get his question answered. Since the communication occurs within our system, both parties’ email addresses remain private. Kind of the way dating sites serve as blind communication intermediaries to protect identities.
All the hiring activity is transparent to both the hiring team and the candidate via a self-generating real-time feed, kind of like you see on Facebook or Twitter. Each candidate has a unique URL for all their activity, visible only to them. In the sequence I just described, the feed for both would show, from most-to-least recent:
“Benjamin replied to the phone screen request”
“Hiring manager requested a phone screen”
“Hiring manager viewed your Tryout”
“123456 uploaded a Tryout submission for your XYZ job”
“Hiring team replied to the Clarification request”
“123456 requested a Clarification”
Presto! No more bias, or “resume black hole.” To see how it works, go to varsidee.com
Hi Mike!
I agree your tool removes some bias but not all there is still bias that can affect the outcome of the test. The way a candidate answers the questions or if the recruiter has had a bad day. This might work for smaller organisations where there is just one or two recruiters that can cross-check each others work but for larger organisations you will see some candidates get passed with the exact same work that another candidate got failed for. I like your solution but it might be better to not focus so much on pointing out bias in Aline’s test when yours also contains bias.
Best,
Benjamin
Hi, Benjamin. Tryout submissions don’t go to recruiters; they go to hiring managers. Recruiters don’t know what it takes to do the job, so they’re stuck with looking for keywords, elite schools, well-known employers, etc.
Your comment suggests that you misunderstand the term “bias.” The definition of bias is “prejudice in favor of or against one thing, person, or group compared with another, usually in a way considered to be unfair.” It means attributing values to an individual based on values you associate with a group to which he belongs, e.g., age, race, gender, ethnic groups, employer affiliation, education, etc.
Hiring managers may have bad days, or not like the way someone answers a question, but that doesn’t constitute bias. Bias requires a comparison that grants an advantage or disadvantage, i.e., one is biased in favor of, or against, one group as opposed to another. Example, I might be biased in favor of younger salespeople vs. older ones, believing they have more energy or stamina. By indulging that bias, I’m assuming that all older salespersons lack energy or stamina. That’s unfair. Or I might be biased in favor of greater experience, believing that older salespeople’s longer experience means they have better judgment. That bias means that I’m attributing superior judgment to all older salespeople, and assuming that all less experienced candidates don’t have it. That’s not fair, either. Whether an individual candidate possesses either of those traits or not is all that matters, and membership in a group (“older” or “younger,” “more experienced” or “less experienced”) is irrelevant. The only legitimate question is, “Does this candidate demonstrate good sales judgment as we define it?” If the company publishes a Tryout Drill scenario that reveals judgment, and they get four submissions that all demonstrate good judgment, and they later learn that three out of the four happened to be younger or less experienced, they’ll have saved themselves from their own experience bias, whereas looking at a resume, they’ll calculate from employment dates the amount of experience candidates have, and associate positive or negative values according to their bias. It really doesn’t matter whether I acquired my sales judgment in six months or sixteen years, only that I have it and can demonstrate it to your satisfaction.
Biases are a form of shorthand that we use to simplify assessments. We use them as indicators in the absence of concrete evidence. “I don’t know if this salesperson has good judgment or not, and I don’t have time to interview everyone, so I’ll draw inferences from these indicators.” Understandable, but not legitimate. Because Tryouts convey concrete evidence of capability, they eliminate the need to draw inferences from any source.
Lets say that you’re looking to hire someone who can make 90% of free throws. During my college basketball career I set records for free throw shooting percentage, regularly exceeding 90%. From that, you infer that I’m a good free throw shooter. But all you really know is that I was a good free throw shooter at that college, under that coach, under those competitive conditions. That doesn’t mean that I can make 90% of my free throws now, under your conditions. Worse, let’s say I didn’t set a measurable record, but I went to a school that has long been reputed to have good free throw shooters. Your confirmation bias causes you to infer from that that I’m a good free throw shooter. Maybe you’re right, maybe you’re not. But I’m going to get the benefit of the doubt because I’m a member of the “went to ABC University” group, whereas your bias will cause you not to consider someone who went to a XYZ College, a school reputed to have poor free throw shooters. What if the candidate from XYZ actually was a poor free throw shooter in college, but has since made himself or herself into a great shooter since then?
Instead of trying draw all these inferences, it’s much fairer and more reliable to not know where I went to school, or even whether I did or not, but simply to put me at the free throw line, hand me the ball, and say, “Shoot 100 free throws” and see how many I make.
That’s what a Tryout does.
Hi there Aline!
I just saw your cool initiative, interviewing.co! You mention “practice algorithms”, how is that part done exactly? And is it only for back-end developers?
Best
Benjamin
Great response Mike. I totally agree with what you said.
Hi, thank you, nice tips.
Interesting perspective. I think hiring the right person is super tricky, but I disagree that big brand name companies are indicative of the quality of an employee. Having worked at some big and some small brand places, I often found I had much more competent coworkers at smaller places. Also, I think resumes are more generic screenings as to whether the person is capable enough to present a passable product (the resume itself). Most technical positions have some sort of exam if you pass the resume phase.
These are very strong data on the fact that people dont give importance to resume writing and how it can affect them negatively.Resume-writing is the foundation of the job-searching process.It must be given much importance and be made impressive.One can always hire a professional resume writer too.
It seems to me that the filterer’s ego is playing too much of a role. What you mention as unclear projects or experience I actually see in reverse. In one, the person is explaining what the project was, in the other the person is explaining what THEY actually did to contribute to the project. I think the Hiring Manager wants to use his knowledge and smarts to guess what was involved with the project, not be told by the candidate. If it’s just a silly recruiter with no tech skills, grammar and spelling might be the only thing they are good at. I also see a lot HR people screen engineers in person because they are not super outgoing – but this has nothing to do with the job.
So basically it’s a huge ego boost to be asked to hire and people seem to abuse the power to sit in judgement of candidates over irrelevant parameters that are just important to them – as if it is a way to win their previous arguments.
While I applaud the exercise of evaluating resumes in relation to hiring, I think the concept expectations of resumes has changed over the years to be less of a professional personal profile to a document that can be scanned and parsed artificially.
Missing in this discussion is the fact that information technology, technical job descriptions border on the absurd. In cases where employers pine for project descriptions (often confidential information), a job-seeker might pine for a concise set of expectations about what will be expected of them.
The broad-based nature of technical resumes is much easier to understand when you realize that applicants use resumes to satisfy a broad pattern of potential employment opportunities.
When employers list 50 or more techno-skills, languages, system artifacts, and so on, the applicant must satisfy the majority of not only that job request but as many as one can legitimately satisfy. The result is resumes that are highly generalized in terms of technology artifacts. Likewise, to appeal to broad cross-sections of employers, experience needs to be worded as benignly as possible. To sound too aggressive, too passive, too egocentric, too deferential, and so on is sure to hurt the job hunting exercise.
IMO, resumes are not personal sales tools but professional positioning devices that help tell potential employers that “I’m in your ballpark”.
Employers who look at resumes looking for resumes to state, “I just did exactly what you want to do for a previous employer” assume that consultant candidates can sustain themselves by never growing or doing something different. And if the candidate is a full-time consideration, why would someone leave the last job to do the same thing elsewhere? This is not an unusual expectation of a candidate or a resume at all – a magic thinking all too prevalent in the industry.
I’m just wondering when a recruiter rejects a resume because it’s “too enterprisey”, what does that mean?
When considering how to write a resume, jobseekers should concentrate on more than just their work experience. An appealing design, clarity of language, and identifying detailed examples that highlight your accomplishments are critical to getting the job you want.
Read on to learn how to write a resume that will tell recruiters and hiring managers a story about what you’ll bring to the table when they hire you.
https://www.hloom.com/how-to-write-a-resume/
Hi Aline, seeing how it has been 4 years since you published this report, and resumes still seem to be stronger than every, do you think they will ever actually die? Or will recruiting and job applications remain as ineffective as ever?
Great article!
I have been looking for the same as i am fresher job seeker and looking for my drean job. So these resume writing tips will be helpful for me to craft a perfect reusme that will led me to get a right job. Thanks a lot for sharing this valuable article!
Resume or cv, one should have to considered many thing before making a resume because its not an easy task you are preparing your life here your way of earning by showing your skills.
seo company
> Hi Aline, seeing how it has been 4 years since you published this report, and resumes still seem to be stronger than every, do you think they will ever actually die? Or will recruiting and job applications remain as ineffective as ever?
Resumes will live forever because hiring managers will be mediocre forever.
Besides, we have written advertisements for things all the time. Brochures, pamphlets, fliers. There s no one strict format for a resume so what makes it any different? You are still trying to sell something to another person.
If the author is intending to convey that the quality of a resume and the quality of the engineer are not relative (my interpretation of suck ), then you absolutely have to remove the perfunctory resumes from the experiment – those resumes are tainting the data. Its advertising like anything else. You wouldn t advertise a movie with a late-night infomercial, so clearly those infomercials serve no purpose, right?
Hey Aline, great data analysis! The “lack of relevant experience” was not surprising at all. I conducted a similar quantitative survey and the results were almost the same as the ones shown here. Resumes suck indeed, but oh well…
Thanks for sharing this experiment. I just wanted to let you know though, I tried to do your online survey that you linked to, and the images to the resumes are broken!
Thanks; will take a look.
Thank you for sharing this information. The experience you share is really great.
Flawed reasoning – maybe the “labels” are wrong – i.e. your grouping to strong or weak might itself be random:
“To make this judgment call, I drew on my personal experience — most of the resumes came from candidates I placed (or tried to place) at top-tier startups. In these cases, I knew exactly how the engineer had done in technical interviews, and, more often than not, I had visibility into how they performed on the job afterwards”
Technical interviews are high variance and inherently flawed – this actually just shows that your personal experience + technical interviews has no correlation with other peoples’ ratings based on resumes.
I also wanted to take the survey and the images are still broken 🙁
I agree with you on false-positives and false-negatives. I was worried more about the latter because the the former can be found out in due course and replaced but once I let slip a good guy, he/she might join a competitor which results in a double whammy for my company.
You have sampled a pool of roughly 100(?) hiring specialists to produce your data set. What is the standard error of your data set? Is more data collection needed before forming any conclusion or interpretting the data set?
Companies are long-term relationships. Treat them like it. Be yourself, and the right match will happen. Put up a facade, and you end up with two facades wasting a lot of time escaping an awkward embrace