I ran technical recruiting at TrialPay for a year before going off to start my own agency. Because I used to be an engineer, one part of my job was conducting first-round technical interviews, and between January 2012 and January 2013, I interviewed roughly 300 people for our back-end/full-stack engineer position.
TrialPay was awesome and gave me a lot of freedom, so I was able to use my intuition about whom to interview. As a result, candidates ranged from self-taught college dropouts or associate’s degree holders to PhD holders, ACM winners, MIT/Harvard/Stanford/Caltech students, and Microsoft, Amazon, Facebook, and Google interns and employees with a lot of people in between.
While interviewing such a wide cross section of people, I realized that I had a golden opportunity to test some of the prevalent folk wisdom about hiring. The results were pretty surprising, so I thought it would be cool to share them. Here’s what I found:
- typos and grammatical errors matter more than anything else
- having attended a top computer science school doesn’t matter
- listing side projects on your resume isn’t as advantageous as expected
- GPA doesn’t seem to matter
And the least surprising thing that I was able to confirm was that:
Of course, a data set of size 300 is a pittance, and I’m a far cry from a data scientist. Most of the statistics here is done with the help of Statwing and with Wikipedia as a crutch. With the advent of more data and more rigorous analysis, perhaps these conclusions will be proven untrue. But, you gotta start somewhere.
Why any of this matters
In the status quo, most companies don’t run exhaustive analyses of hiring data, and the ones that do keep it closely guarded and only share vague generalities with the public. As a result, a certain mysticism persists in hiring, and great engineers who don’t fit in “the mold” end up getting cut before another engineer has the chance to see their work.
Why has a pedigree become such a big deal in an industry that’s supposed to be a meritocracy? At the heart of the matter is scarcity of resources. When a company gets to be a certain size, hiring managers don’t have the bandwidth to look over every resume and treat every applicant like a unique and beautiful snowflake. As a result, the people doing initial resume filtering are not engineers. Engineers are expensive and have better things to do than read resumes all day. Enter recruiters or HR people. As soon as you get someone who’s never been an engineer making hiring decisions, you need to set up proxies for aptitude. Because these proxies need to be easily detectable, things like a CS degree from a top school become paramount.
Bemoaning that non-technical people are the first to filter resumes is silly because it’s not going to change. What can change, however, is how they do the filtering. We need to start thinking analytically about these things, and I hope that publishing this data is a step in the right direction.
Method
To sort facts from folk wisdom, I isolated some features that were universal among resumes and would be easy to spot by technical and non-technical people alike and then ran statistical significance tests on them. My goal was to determine which features were the strongest signals of success, which I defined as getting an offer. I ran this analysis on people whom we decided to interview rather than on every applicant; roughly out 9 out of 10 applicants were screened out before the first round. The motivation there was to gain some insight into what separates decent candidates from great ones, which is a much harder question than what separates poor candidates from great ones.
Certainly there will be some sampling bias at play here, as I only looked at people who chose to apply to TrialPay specifically, but I’m hoping that TrialPay’s experience could be a stand-in for any number of startups that enjoy some renown in their specific fields but are not known globally. It also bears mentioning that this is a study into what resume attributes are significant when it comes to getting hired rather than when it comes to on-the-job performance.
Here are the features I chose to focus on (in no particular order):
- BS in Computer Science from a top school (as determined by U.S. News and World Report)
- Number of grammatical errors, spelling errors, and syntactic inconsistencies
- Frequency of buzzwords (programming languages, frameworks, OSes, software packages, etc.)
- How easy it is to tell what someone did at each of their jobs
- Highest degree earned
- Resume length
- Presence of personal projects
- Work experience in a top company
- Undergraduate GPA
TrialPay’s hiring bar and interview process
Before I share the actual results, a quick word about context is in order. TrialPay’s hiring standards are quite high. We ended up interviewing roughly 1 in 10 people that applied. Of those, after several rounds of interviewing (generally a phone screen followed by a live coding round followed by onsite), we extended offers to roughly 1 in 50, for an ultimate offer rate of 1 in 500. The interview process is pretty standard, though the company shies away from asking puzzle questions that depend on some amount of luck/clicking to get the correct answer. Instead, they prefer problems that gradually build on themselves and open-ended design and architecture questions. For a bit more about what TrialPay’s interview process (used to) look like, check out Interviewing at TrialPay 101.
The results
Now, here’s what I discovered. The bar height represents effect size. Every feature with a bar was statistically significant. These results were quite surprising, and I will try to explain and provide more info about some of the more interesting stuff I found.
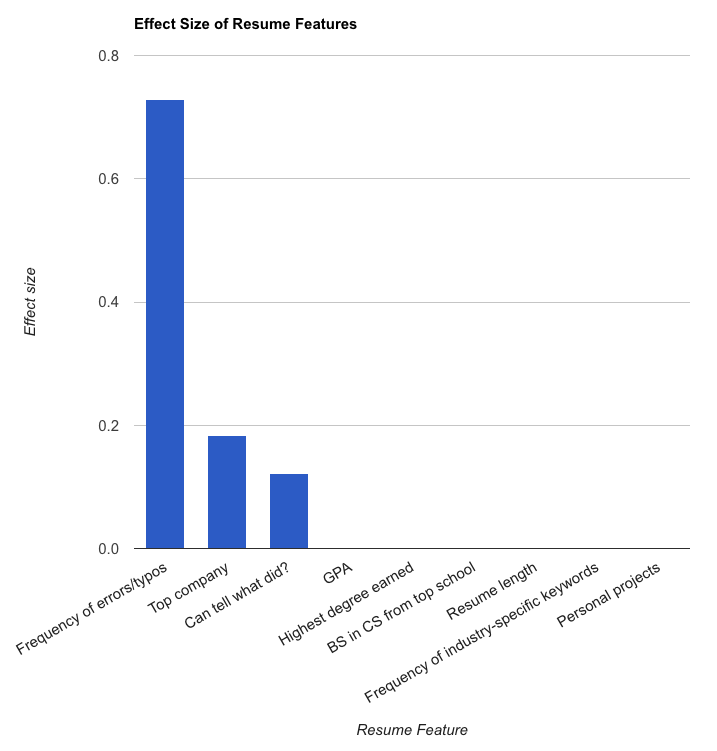
The most significant feature by far was the presence of typos, grammatical errors, or syntactic inconsistencies.
Errors I counted included everything from classic transgressions like mixing up “its” and “it’s” to typos and bad comma usage. In the figure below, I’ve created a fictional resume snippet to highlight some of the more common errors.

This particular result was especially encouraging because it’s something that can be spotted by HR people as well as engineers. When I surveyed 30 hiring managers about which resume attributes they thought were most important, however, no one ranked number of errors highest. Presumably, hiring managers don’t think that this attribute is that important for a couple of reasons: (1) resumes that are rife with mistakes get screened out before even getting to them and (2) people almost expect engineers to be a bit careless with stuff like spelling and grammar. With respect to the first point, keep in mind that the resumes in this analysis were only of people whom we decided to interview. With respect to the 2nd point, namely that engineers shouldn’t be held to the same writing standards as people in more humanities-oriented fields, I give you my next chart. Below is a breakdown of how resumes that ultimately led to an offer stacked up against those that didn’t. (Here, I’m showing the absolute number of errors, but when I ran the numbers against number of errors adjusted for resume length, the results were virtually identical.)
If you want to play with these histograms, just click on the image, and an interactive version will pop up in a separate window.
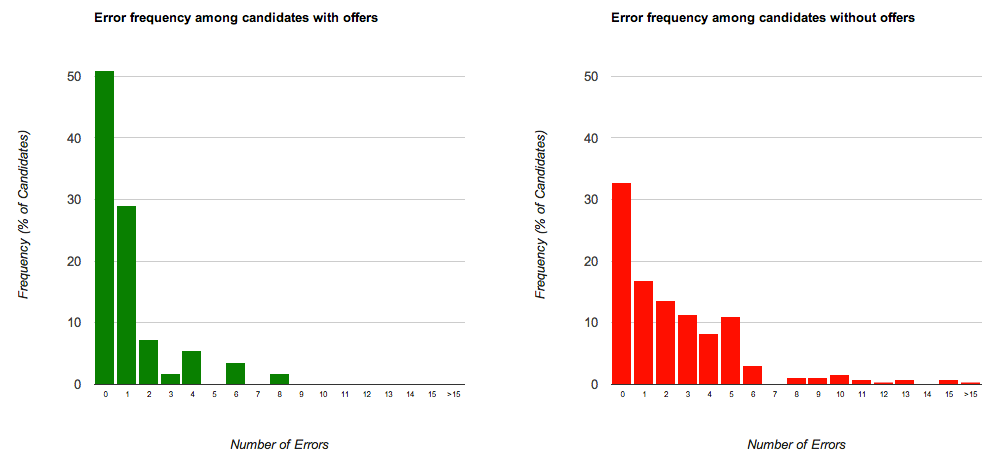
As you can see, the distributions look quite different between the group of people who got offers and those that didn’t. Moreover, about 87% of people who got offers made 2 or fewer mistakes.
In startup situations, not only are good written communication skills extremely important (a lot of heavy lifting and decision making happens over email), but I have anecdotally found that being able to write well tends to correlate very strongly with whether a candidate is good at more analytical tasks. Not submitting a resume rife with errors is a sign that the candidate has strong attention to detail which is an invaluable skill when it comes to coding, where there are often all manners of funky edge cases and where you’re regularly being called upon to review others’ code and help them find obscure errors that they can’t seem to locate because they’ve been staring at the same 10 lines of code for the last 2 hours.
It’s also important to note that a resume isn’t something you write on the spot. Rather, it’s a document that you have every opportunity to improve. You should have at least 2 people proofread your resume before submitting it. When you do submit, you’re essentially saying, “This is everything I have done. This is what I’m proud of. This is the best I can do.” So make sure that that is actually true, and don’t look stupid by accident.
No surprises here. The only surprise is that this attribute wasn’t more significant. Though I’m generally not too excited by judging someone on pedigree, having been able to hold down a demanding job at a competitive employer shows that you can actually, you know, hold down a demanding job at a competitive employer.
Of all the companies that our applicants had on their resumes, I classified the following as elite: Amazon, Apple, Evernote, Facebook, Google, LinkedIn, Microsoft, Oracle, any Y Combinator startup, Yelp, and Zynga.
After I ran the numbers to try to figure out whether GPA mattered, the outcome was a bit surprising: GPA appeared to not matter at all. Take a look at the GPA distribution for candidates who got offers versus candidates that didn’t (click to get a bigger, more interactive version).

As a caveat, it’s worth mentioning that roughly half of our applicants didn’t list their GPAs on their resumes, so not only is the data set smaller, but there are probably some biases at play. I did some experiments with filling in the missing data and separating out new grads, and I will discuss those results in a future post.
Is it easy to tell what the candidate actually did?
Take a look at this role description:

Now take a look at this one:

In which of these is it easier to tell what the candidate did? I would argue that the first snippet is infinitely more clear than the second. In the first, you get a very clear idea of what the product is, what the candidate’s contribution was in the context of the product, and why that contribution matters. In the second, the candidate is using some standard industry lingo as a crutch — what he said could easily be applied to pretty much any software engineering position.
Judging each resume along these lines certainly wasn’t an exact science, and not every example was as cut-and-dry as the one above. Moreover, while I did my best to avoid confirmation bias while deciding whether I could tell what someone did, I’m sure that the system wasn’t perfect. All this said, however, I do find this result quite encouraging. People who are passionate about and good at what they do tend to also be pretty good at cutting to the chase. I remember the feeling of having to write my resume when I was looking for my first coding job, and I distinctly remember how easily words flowed when I was excited about a project versus when I knew inside that whatever I had been working on was some bullshit crap. In the latter case is when words like “software development life cycle” and a bunch of acronyms reared their ugly heads… a pitiful attempt to divert the reader from lack of substance by waving a bunch of impressive sounding terms in his face.
This impression is further confirmed by a word cloud generated from candidate resumes that received an offer versus those that didn’t. For these clouds, I took words that appeared very frequently in one data set relative to how often they appeared in the other one.


As you can see, “good” resumes focused much more on action words/doing stuff (“manage”, “ship”, “team”, “create”, and so on) versus “bad” resumes which, in turn, focused much more on details/technologies used/techniques.
Highest degree earned

Though highest degree earned didn’t appear to be significant in this particular data set, there was a definite trend that caught my attention. Take a look at the graph of offers extended as a function of degree.
Mobile users, please click here to view this chart.
As you can see, the higher the degree, the lower the offer rate. I’m confident that with the advent of more data (especially more people without degrees and with master’s degrees), this relationship will become more clear. I believe that self-motivated college dropouts are some of the best candidates around because going out of your way to learn new things on your own time, in a non-deterministic way, while juggling the rest of your life is, in some ways, much more impressive than just doing homework for 4 years. I’ve already ranted quite a bit about how worthless I find most MS degrees to be, so I won’t belabor the point here.1
BS in Computer Science from a top school
But wait, you say, even if highest degree earned doesn’t matter, not all BS degrees are created equal! And, having a BS in Computer Science from a top school must be important because it’s in every fucking job ad I’ve ever seen!
And to you I say, Tough shit, buddy. Then I feel a bit uncomfortable using such strong language, in light of the fact that n ~= 300. However, roughly half of the candidates (122, to be exact) in the data set were sporting some fancy pieces of paper. And yet, our hire rate was not too different among people who had said fancy pieces of paper and those that didn’t. In fact, in 2012, half of the offers we made at TrialPay were to people without a BS in CS from a top school. This doesn’t mean that every dropout or student from a 3rd rate school is an unsung genius — there were plenty that I cut before interviewing because they hadn’t done anything to offset their lack of pedigree. However, I do hope that this finding gives you a bit of pause before taking the importance of a degree in CS from a top school at face value.

In a nutshell, when you see someone who doesn’t have a pedigree but looks really smart (has no errors/typos, very clearly explains what they worked on, shows passion, and so forth), do yourself a favor and interview them.
Of late, it’s become accepted that one should have some kind of side projects in addition to whatever it is you’re doing at work, and this advice becomes especially important for people who don’t have a nice pedigree on paper. Sounds reasonable, right? Here’s what ends up happening. To game the system, applicants start linking to virtually empty GitHub accounts that are full of forked repos where they, at best, fixed some silly whitespace issue. In other words, it’s like 10,000 forks when all you need is a glimmer of original thought.

Yay forks.
Outside of that, there’s the fact that not all side projects are created equal. I can find some silly tutorial for some flashy UI thing, copy the code from it verbatim, swap in something that makes it a bit personal, and then call that a side project on my resume. Or I can create a new, actually useful JavaScript framework. Or I can spend a year bootstrapping a startup in my off hours and get it up to tens of thousands of users. Or I can arbitrarily call myself CTO of something I spaghetti-coded in a weekend with a friend.
Telling the difference between these kinds of projects is somewhat time-consuming for someone with a technical background and almost impossible for someone who’s never coded before. Therefore, while awesome side projects are a HUGE indicator of competence, if the people reading resumes can’t (either because of lack of domain-specific knowledge or because of time considerations) tell the difference between awesome and underwhelming, the signal gets lost in the noise.
Conclusion
When I started this project, it was my hope that I’d be able to debunk some myths about hiring or at least start a conversation that would make people think twice before taking folk wisdom as gospel. I also hoped that I’d be able to help non-technical HR people get better at filtering resumes so that fewer smart people would fall through the cracks. Some of my findings were quite encouraging in this regard because things like typos/grammatical errors, clarity of explanation, and whether someone worked at an elite company are all attributes that a non-technical person can parse. I was also especially encouraged by undergraduate pedigree not necessarily being a signal of success. At the end of the day, spotting top talent is extremely hard, and much more work is needed. I’m optimistic, however. As more data becomes available and more companies embrace the spirit of transparency, proxies for aptitude that don’t stand up under scrutiny will be eliminated, better criteria will take their place, and smart, driven people will have more opportunities to do awesome things with their careers than ever before.
Acknowledgements
A huge thank you to:
- TrialPay, for letting me play with their data and for supporting my ideas, no matter how silly they sounded.
- Statwing, for making statistical analysis civilized and for saving me from the horrors of R (or worse, Excel).
- Everyone who suggested features, helped annotate resumes, or proofread this monstrosity.
EDIT: See Hacker News for some good discussion.
1It is worth mentioning that my statement about MS degrees potentially being a predictor of poor interview performance does not contradict this data — when factoring in other roles I interviewed for, especially more senior ones like Director of Engineering, the (negative) relationship is much stronger.
Looking for a job yourself? Work with a recruiter who’s a former engineer and can actually understand what you’re looking for. Drop me a line at aline@alinelerner.com.
I’m not statistics expert, but wouldn’t it be better for the “top school” measure to compare only people who have obtained a CS degree? The prior measure already shows that, in your data, that having such a degree is not a good predictor, but you would isolate whether a top school influences things by only comparing degrees.
Aline, you awesome! I love you articles.
Thanks Aline. I found this really interesting. I too used to be an engineer and am now a technical recruiter. My company also takes an unorthodox approach to hiring and looking for talent that keeps my job very interesting. I have not run statistics, but I also find that I naturally dismiss resumes with several errors as well as ones that drone on with buzzwords and no substance. I could care less about degrees and GPAs. We have an incredibly smart and talented team of designers and engineers with incredibly diverse backgrounds. Some took the traditional route of a CS degree from an elite university and others never went to college. Some came from reputable companies and others were delivering pizza. One of the most important factors to me is maintaining our awesome company culture. No arrogant jerk engineer will make it past me 🙂
You indicate in the ‘context’ that TrialPay had a 1:50 offer rate – one offer per 50 candidates interviewed. Just to confirm – that implies that your population of 300 interviewees resulted in a total of 6 offers extended? Do you have any data to share about how many of those offers were accepted?
A few thoughts:
1) In the section on GPA, it looks to me like 66% of offers went to candidates with a 3.8 or higher GPA and 30% of non-offers went to candidates with 3.8 GPA or higher. Am I misunderstanding? That seems like it’s significant.
2) In the word cloud, I can’t really tell the difference between the words. In the “offer” pile, I see “developer” and “develop”, but in the “no offer” pile I see “developed”. Likewise, “engineering” is an offer-worthy word, but “research” is not, but they’re both action words. I think laying out the words in 2 side-by-side lists by frequency might be more instructive.
Good questions.
1) No, you’re not misunderstanding. Thing is, not everyone provided their GPA, so the data set ended up being smaller than the original 300 (about half). I tried playing around with filling in missing data with a few different techniques, and that will be the subject of a future post.
2) You’re right that the word clouds aren’t as unambiguously different as they should be to really a strong, unequivocal difference between the groups. This is also something I hope to revisit with the advent of more data. Btw, doing side-by-side lists by frequency was the very first thing I tried, but because eng resumes, in general, have a LOT of overlap, that approach didn’t really get anything interesting.
Great post; it’s rare to find this kind of information about hiring (or, say college admissions) made public. One caveat though is the supreme confidence you have in the interview process. For instance, although your interviewers do not find college degrees matter (conditioned on applying), that does not mean it has no effect on programmer quality. For this stronger statement to hold true, you’d need data on performance after hiring.
Definitely. That’s something I very much hope to do in the future.
If I were considering hiring a native speaker of English, a single homonym misuse (its/it’s, effect/affect, et c.) would be sufficient for a NO HIRE in my book.
Good post! How did you determine top/”elite” companies? Were there others that made it to that list?
A lot of that was very subjective. It was a mix of industry-specific knowledge and past experiences that hiring managers had had with candidates from specific companies. Definitely not the most scientific approach, but I was trying to echo what others in my position might think to see if that variable held up.
Aline, I definitely think you are on to something here. Data Science could be an intriguing proposition to hiring data especially for recruiters. If you need R assistance I could point you in the right direction.
Interesting article, but I have a question: how do you account for “nativeness” bias?
If grammatical errors are the big factor, wouldn’t that make all the non native engineers out by default just because English is not their primary language?
I ask this because I have work with some great people that cannot type for the life of them.
There was some good discussion of this point on Hacker News a few days go. I think that the key difference is that a resume isn’t a document you prepare on the fly. Rather you have ample opportunity to have it proofread. I think anyone could benefit from a 2nd or 3rd pair of eyes on their resume, whether they’re a native speaker or not.
The personal project thing seemed a bit surprising to me at first, but your signal to noise comparison hit it home for me.
Do you think personal projects would be easier to distinguish if, instead of using GitHub, projects were described in brief on a personal page (i.e., http://www.myname.com/projects)? This would perhaps provide a more distinctive ”signal” amongst all the GitHub forkers out there.
Did you encounter applicants that linked to projects hosted on personal web pages? If so, do you feel this approach was better at communicating the quality of the project(s) claimed by the applicant?
I think that any clear explanation of what a project does, what the motivation for building it was, and what some of the challenges were is extremely useful and helpful for both technical and non-technical audiences. Some of this is accomplished with good comments, which is also great.
> Engineers are expensive and have better things to do than read resumes all day.
I think this is either a) just not true, or b) citation needed.
Of course they are expensive, but not when considering the net cost of all hires. And if they take all day to read resumes then … they are really slow readers.
I found this very interesting and was buoyed by the results of the data especially “typos and grammatical errors matter more than anything else” (a pet peeve of mine) and having a top degree was not a guarantee of employment or success. Some things that I’ve long believed were true but couldn’t quantify. There are legions of intelligent, successful people (not just engineers although this was the focus here) in all aspects of business. Time for the ‘young’uns’ to sit up and take note if they are to make it in today’s business climate
Thanks for a very interesting article. For the benefit of your non-American readers could you please explain what they mysterious GPA abbreviation stands for?
GPA = grade point average
“At most schools, colleges and universities in the United States, letter grades follow a five-point system, using the letters A, B, C, D and E/F, with A indicating excellent, C indicating average and E/F indicating failing. Additionally, most schools calculate a student’s grade point average (GPA) by assigning each letter grade a number and averaging those numerical values. Generally, American schools equate an A with a numerical value of 4.0.”[1]
[1]http://en.wikipedia.org/wiki/Grading_(education)#United_States
Different employers have very different approaches. Companies that value analytical skills will seldom hire a non-graduate over a graduate, all else being equal. And there are definitely some employers that consider engineering time put into screening graduates well worth the expense – examples include Amazon and Google.
@DC: the variation you indicate for GPA for hired-nonhired would be statistically significant even with quite low numbers. Since the smallest fraction in the “hired” graph is 8.3%, which is about 1/12, it’s reasonable to suppose that the sample is at least 12. If you do a binomial p-value calculation on significance of this difference based on N=12 from the “not hired” fraction, you get p < 0.01. That these numbers don’t square with the claim that only 6 out of 300 (and only half supplied GPAs) were made offers suggests to me some errors in the analysis.
The key take-home from this is that selling yourself can make a big difference, especially if you are pitching to recruiters who are not technically competent. It is of course not a given that hiring decisions are right; a good follow-up study would be correlating success of the candidate to these measures. I know a self-made billionaire who lost his job because he didn’t fit the corporate image of an ideal employee.
A bit of clarification is in order. We made offers to 6 people. I also brought in resumes from current and past employees, and where possible, past offers extended, such that there would be a few more positive data points in the data set (for a total of 23, 6 of which were new and 17 of which were old). That, of course, comes with its own flaws but should account for the discrepancy you observed.
I’m going to fix the post to make this info explicit. Thank you for calling it out!
I agree that being a grad is a strong signal. It’s just that there may very well be other strong signals that are currently being overlooked in favor of one that is so easy to spot.
Thanks for conducting an interesting analysis using resume data. More such studies are needed.
When i look over my own recruiting strategy, i tend to do the following:
1) Spelling mistakes don’t create a good impression but i understand that programming today is a global activity and not everyone had the luck to have english as their first language. In my own case, it only comes in third.
2) Never, ever let a HR do the filtering ( and make sure that HR has some technical folks with them during the process ). I can do this due to me being their boss and having learned this lesson the hard way.
3) Never, ever be satisfied with interviews alone. Make the developer spend some paid time with the development team, have fun, write some open source code, debug some open source code, and just chill. Then the development teams make a strong case ( and can even override me if they make a good pitch for a candidate 🙂
4) Collage degrees are not totally useless but they are not all that they are made out to be. I don’t see too much correlation between every ivy league schools and performance on the job.
5) To me, the most important trait for a programmer is their determination to get the job done even if its a fairly long project. They need to love that aspect of the job. They need
to constantly explore the technology landscape, keeping them abrest of happenings.
6) Even work experience in top companies only carries them so far. To me, i do my best not
to be influenced by the past ( both my own and the candidate’s ) and try my best to evaluate performance on an ongoing basis and take action based on that.
Just some random thoughts.
I would be curious to see an analysis of some of these data points, as compared to their actual offer (base + benefits). Specifically, I wonder whether some of the “pedigree” aspects play more of a role at attaining a higher salary, even if they don’t play as much of a role in the role of getting an offer. (additional data points could be included for offers extended vs accepted, counters, etc… but I suspect that it would end up cluttering the results more than it would provide valuable results)
I think it’s wrong to group up engineers into this giant bucket to make assumptions on. Specifically I’m looking at the Offer vs No Offer word clouds. When “Javascript” is in the Offer bucket and “C++” is in the No Offer, where both are programming languages. Also depending on seniority of the position, GPA will matter far more for a junior position and less to none for a senior/manager.
Hiring isn’t really a popularity contest (though it can be). It is accurately portraying yourself to match the needs of the organization. Even if the job isn’t as popular (a back-end data scientist for example with no direct relationship to the end user).
That bar isn’t really “high” – you have an artificially-constrained pool, so a “1 in 500” offer rate isn’t that impressive.
If all developers applied for your position, you could get a good number, but it’s like colleges who claim to only have a 5% acceptance rate – that *sounds* amazing … but it’s not that impressive – on its own.
The true top of the batch already have jobs (most likely), and aren’t really “hunting”, they’re maybe being found, but not necessarily out looking for new opportunities.
That said, definitely the grammar and spelling on CVs and similar is vital: communication is far more important than programming – if you can’t communicate, it doesn’t matter how awesome you are otherwise .. no one can ever find out.
The related post you should reference: http://www.joelonsoftware.com/articles/findinggreatdevelopers.html
Awesome post..shared with fellow CS majors at UC Berkeley! 🙂
Thank you!!
I’m having a bit of trouble understanding how all of your data fits together. You say that 20% of the candidates without a degree got an offer. In the next paragraph you say that 122 of the 300 people who applied had degrees. This would apply that .2*178=35 people without degrees got offers. Yet you just said in the comments that only 23 people were given offers? Are you drawing from an even larger data set for these statistics?
Sorry, that was totally unclear. What I meant was that 122 people had a BS in CS from a top school (as opposed to a degree in the more general sense). Only 10 people in the study didn’t have any degree to speak of, and of those, 2 got offers. I know that these numbers are very, very low, so the part about highest degree earned was very speculative and definitely requires more data; as you can see, that attribute didn’t actually end up achieving significance.
Well Said, How about Certifications? does they matter?
” I believe that self-motivated college dropouts are some of the best candidates around because going out of your way to learn new things on your own time, in a non-deterministic way, while juggling the rest of your life is, in some ways, much more impressive than just doing homework for 4 years.”
Really? Is that all you did while studying? No certifications? No self-learning? No engagements in student organisations? No gained experiences from project and team work? I for once was actually self-motivated to go to collage. No one forced me. I’ve juggled my personal life, student engagements (leader roles), ‘teacher’s assistant’ positions, four part-time jobs, engagement with startups, volunteering, pro bono work, an ‘hands on’ Bachelor thesis for the largest IT consultancy company in the world, and more for the last three years (Scandinavian bachelor’s degree) with mostly A’s on my diploma. If there’s more “impressiveness” in sitting at home reading computer science books than what I’ve done, then I don’t believe I need ‘that job’.
While we’re nit-picking: why do you consider “frauds” to be “incorrect pluralization” here? According to my dictionary, the word can be used both as an uncountable noun to refer to the general act, and as a countable noun to refer to a person who practices it.
A quick search on Google Books shows that there are many published books from highly educated and respected authors who use the phrase “to detect frauds.”
I think there is even one more typo hidden in your resume extract below the headline ‘Number of errors’. The candidate wrote ‘synched’, but the correct spelling would be ‘synced’.
Sorry for my bean counting, i’m just that detail oriented and could not stand to leave that unmentioned. 😉
I agonized over this when I wrote the post. It turns out they’re both correct 🙂
The Yeezie quote is the icing on the cake.
Wow!!. Quite an interesting article here. i wish all so called “recruiters” could read it.
I believe your right. Have not collected the data but as a technical recruiter myself i see your points very agreeable. i would say most the better candidates have at least 2 to 3 internships and are able to articulate what they did at the internship or co-op.
Not that I disagree with your conclusions, but did you check to make sure that you didn’t run into a correlation fallacy?
Candidates who are a good fit don’t need to do linguistic gymnastics or verbal abstractions when talking about their work. Instead of editing their resume to fit the role they are applying for, they simply talk about what they do in a more comfortable and candid manner. Because they don’t spend so much energy trying to bend their experience, they can place their focus on minor things (like grammar) and not major things (like “how do I say ____ so that it seems like I do _____). They also usually are more disciplined, have placed a higher priority on your company, etc…
The same practice of typo screenings is done by slush readers and book publishers when manuscripts are sent to them–not because its a great way to gauge talent, but its a great way to gauge commitment and focus.
Good list overall–but if you ever get the chance, wouldn’t the experiment be better if people were given only resumes of people who were actually given offers (as well as a separate study where 100% of the resumes are specifically people that have been rejected)?
If 100% of the resumes are known to be from candidates that were good enough to be offered, the results would be more telling if only (100-X)% of candidates are deemed “qualified” to be talked to. The value of X would be better able to determine how well each group was able to identify resumes as good or not. The result should be that 100% of the resumes be deemed qualified for an interview–but if X% of resumes are deemed unqualified, then you can know what “bias hurdle” each group projects that prevents good candidates from being interviewed. After that, doing a second study where 100% of resumes are rejected candidates allows you to find out what “bias” each group projects that allows bad candidates from getting past the filter.
As a bonus, comparing the results of those two studies with your current study (wherein 64% of the candidates are deemed “good”) can better reveal what biases each case group projects depending on the resume pool. Do they make better predictions when their resume pool is good (showing the importance of dedicated sourcers), do they make better predictions when resumes are bad (showing the importance of job boards and email blasts), or do they do better with your mixed pool of resumes.
That way, you can enact a recruiting methodology that places emphasis on candidate pool creation instead of simply resume screening practices.
Great work regardless!
These would be great followup studies. If I can get enough data, I’ll do my best to make it happen.
Did employers have any interested in the candidates Stackoverflow rating?
In addition to Kevin’s suggestion of additional studies, I think you should do another study that looks at how well the new-hires work out. Because right now, you are just looking at correlation between being hired and certain resume features. This is definitely worth knowing, but it is also important to know if it has any correlation to developer productivity.
Some books that have addressed this issue to some degree are “Facts and Fallacies of Software Engineering” by Robert L. Glass and “Work Rules” by Laszlo Bock. I would recommend you read “Work Rules”. It is far from perfect, but at least Bock is on the right track when he says:
“Most interviews are a waste of time,” he writes, “because 99.4% of the time is spent trying to confirm whatever impression the interviewer formed in the first 10 seconds.”
He explains that interviewers do this by asking questions like, “Can you tell me about yourself?” “What is your greatest weakness?” and “What is your greatest strength?”
In other words, he writes, most of what we think of as “interviewing” is “actually the pursuit of confirmation bias.”
So, the lesson here is this: Yes, you always need to make a killer first impression — but it’s just as imperative that you maintain and reinforce it throughout the entire conversation.
http://finance.yahoo.com/news/google-hr-boss-explains-why-163700153.html
In another article published in the NY Times:
LAST June, in an interview with Adam Bryant of The Times, Laszlo Bock, the senior vice president of people operations for Google — i.e., the guy in charge of hiring for one of the world’s most successful companies — noted that Google had determined that “G.P.A.’s are worthless as a criteria for hiring, and test scores are worthless. … We found that they don’t predict anything.” He also noted that the “proportion of people without any college education at Google has increased over time” — now as high as 14 percent on some teams. At a time when many people are asking, “How’s my kid gonna get a job?” I thought it would be useful to visit Google and hear how Bock would answer.
Don’t get him wrong, Bock begins, “Good grades certainly don’t hurt.” Many jobs at Google require math, computing and coding skills, so if your good grades truly reflect skills in those areas that you can apply, it would be an advantage. But Google has its eyes on much more.
“There are five hiring attributes we have across the company,” explained Bock. “If it’s a technical role, we assess your coding ability, and half the roles in the company are technical roles. For every job, though, the No. 1 thing we look for is general cognitive ability, and it’s not I.Q. It’s learning ability. It’s the ability to process on the fly. It’s the ability to pull together disparate bits of information. We assess that using structured behavioral interviews that we validate to make sure they’re predictive.”
…
http://www.nytimes.com/2014/02/23/opinion/sunday/friedman-how-to-get-a-job-at-google.html?_r=2
Fun stuff, and a step in the right direction. Some pointers on future improvement:
1) By including only the pre-screen passing resumes in the data set you’ve already introduced a ton of bias. Broaden the data set to all applicants. This is especially important for features like educational attainment and pedigree, since these are important parts of the pre-screen criteria. In order to pass the pre-screen, the non-pedigreed applicants who made it into your data set obviously had outstanding characteristics in other areas that made up for the lack of pedigree.
2) Also be wary of self-selection bias. This can come out in the GPA analysis in a big way. Applicants will only report their GPA if they think it is an asset. That’s why virtually nobody reported GPAs lower than 3.2. Self-reporting a B+ or higher GPA puts you in a top tier where there is likely more variation in competency between your tier and the next tier than there is within your tier. If you had data on all the 2.0s and 2.5s and such I bet you would see a statistically significant correlation.
I agree with most of this article but would like to point out that a university degree in any STEM subject is far far more than a “fancy piece of paper”.
This kind of language is a slap in the face to thousands of IT professionals all over the world. Just because it is now possible to learn (insert-latest-javascript-framework-here) in a week and call yourself a programmer does not invalidate over forty years of computer science research by some of the smartest people to have ever walked this Earth.
I hear this all the time – why is it only a “fancy piece of paper” when it’s an IT degree? Degrees in geology, mathematics, medicine, law, civil engineering, physics and chemistry are all required in their respective fields – are these also to be devalued as useless?
Achieving a computer engineering/electrical engineering/computer science/software engineering degree from any university is not the result of doing “homework for 4 years”.
It’s actually a lot of fucking hard work.
I learned many things at university that I still use 20 years later. I also learned many things that I’ve never used. I’m not suggesting that a CS degree is necessary or even necessarily useful to have a successful IT career but this kind of language disgusts me.
I sincerely hope you change your attitude – we have enough trouble with recruiters in IT as it is.
I’m not trying to derogate the degree. I just don’t like degrees being used as a high-signal gating mechanism for jobs… despite having an engineering degree myself.
As a CS degree holder, I’d say:
An engineering degree is needed to build a bridge. But it is not needed to build a toy bridge.
99% of the software being built today is toy quality software. If you are hiring for a new whizbang website (i’m looking at you, Facebook), you don’t need people with a degree for most of your jobs. If you are hiring to design a flight avionics system with lives on the line, I hope a CS degree from a reputable institution is mandatory for every hire.
Thanks for your reply – and look in essence I agree.
But here’s my follow up question: would you apply the same logic if you were trying to place an astronomer, a lawyer or a mechanical engineer?
Probably not – because it isn’t currently acceptable to be self taught in these older fields. You could get away with it in the 60s & 70s (and even then only maybe) but not today.
But due to demand outstripping supply in the 90s it became fashionable to write off formal IT training – it *had* to be just a “piece of paper”, it *had* to be devalued as worthless – by business people, by recruiters and by IT workers who lacked such qualifications.
Because …well what was the alternative?
And since then CS departments all over the world have been struggling to maintain relevance – they were just as surprised as all of us in 1995 when it all went nuts – still teaching out of date languages, overly formal proofs of schema validity, unused/unadopted network protocols etc etc.
So as I said in my earlier post, I don’t claim that it should be required to have an IT degree. At least not until we gain some maturity as a professional industry (and now that Node.js is apparently here to stay, well…*that’s* looking more unlikely than ever – queue the flaming 🙂
I simply object to it being written off as a waste of time – and not as some kind of retrospective self justification (I couldn’t give a rats bum what people think of me at this stage in my life) – but as a professional who has spent much of my career unfucking systems “architected” by the self-taught crowd, it’d be nice if maybe, just maybe, we could maintain a scintilla of dignity.
After all we actually designed and built most of the systems in use today. We have much to be proud of – it’s been a wild ride.
That’s it and that’s all 🙂
Thanks again – I’m chucking out my soapbox now.
I agree with everything you said. I think the main difference between the fields you mentioned and software, besides the newness of the field (the very newness that makes wild west-type approaches to hiring possible), is that there’s a lot less infrastructure needed to get started. If you’re doing mechE, you probably need some hardware, access to expensive software etc. With programming, you just need a browser, a text editor, and an internet connection, so it’s easier to teach yourself. That doesn’t mean that teaching yourself is always awesome or that degrees are shit. I just don’t think degrees are the best gating mechanism.
And god knows I want an interview process that weeds out people who produce spaghetti code. But I’d argue they come from schools as well as autodidactic channels.
Very interesting read, and good to see that you’re applying analytical techniques to hiring data. However, good analytics also requires good methodology, so here are some points for improvement:
1. First of all, your dependent variable: job offer or not. From a construct validity perspective, this variable tells you what the recruiters involved are paying attention to, not what separates successful engineers from the non-successful. This is important. As someone suggested, looking at post-hire variables indicative of success, or ‘talent’ (more questionable though) is really the way forward.
2. Maybe I missed it, but you have seemed to be looking at all of the independent variables separately. The real interesting question here is to model the variance/covariance of the independents relative to the dependent. That means, factoring out the unique contribution of each variable in relation to your dependent variable. Since your dependent var is binary, job offered or not, a simple logistic regression should get you started. If you need tips on doing this in R, let me know.
3. Maybe you could include some measures related to the job offer itself. I mean, the jobs that have been screened against are likely to differ: at start-ups, as a team-leader or not, job-content (maybe in some classes). These might be mediators for some of the effects you are finding. Maybe having worked at a top-company matters when screening for a job for….a top-company. Maybe GPA matters for some job-contents more than for others. So just maybe, the lack of variation in the sort of jobs you and the team were recruiting for explains some your surprising findings.
Hope this keeps you going at this.
Cheers,
Bernie.
Thanks; agree wholeheartedly with everything you said.
I will add that in addition to the concerns you raised in (1), this study suffers from a good amount of selection bias.
Sadly there wasn’t enough data at the time to split things further than we did, as we were primarily looking at just one role.
Re (2), a logistic regression was one of the first things I did, but as I recall (this was a long time ago now :/) I wasn’t happy with how the data fit and decided to look at the independent vars separately.
I pay a quick visit daily a few web sites and blogs to read articles,
however this weblog offers quality based articles.
Obviously have a competent resume service prepare your resume will give you a leg up.
The most important item I got from this study is: That grammar and spelling are very important. My experience with coding would tend to support that. One small error will make a program or web site not work properly.
Thanks Aline, These are really interesting results.
Re: Frequency of errors on the resume, I’m not sure about the analysis that this variable had the highest impact. I suspect that because this is a numeric value going up to >15 while most of the other variables that had a chance of mattering are either binary or small closed classes. Depending on the statistical methods you used, that might have caused this variable to be weighed more heavily.* Looking at the error frequency graphs, it looks like from 0-8 errors, the shape of the curve is roughly the same (albeit with more data in the no-hire bucket.) The difference is that the no-hire has a long tail. I would recommend rerunning the analysis with error frequency being bucketed to low/high with 7 as the cuttoff, or perhaps, 0/low/high, since 0 is discontinuous with 1-7 on both curves. Then see if that’s the most predictive variable.
It would be super valuable if you included details of your statistical methods in your methods section so readers can understand how to interpret your results. Thanks for including the graphs, that helps a lot in interpretation.
* I’m not a statistician nor do I play one on TV, but I know enough to be dangerous.
Hey, Aline, thanks for this wonderful article!
Reading this has really given me some hopes. I am actually looking into expanding my career in programming by learning online but doubtful because of the fact that my undergrad course (Law Enforcement) is leagues different from those that actually get to work as programmers. I am still doubtful if learning on my own and enrolling online programming classes are not enough to get me to apply for big companies.
Another resource I have recently read that really gave me a pause is this one. Some of your readers might find this article helpful the next time they interview or craft their job posts.
This is the perfect site for everyone who wishes to find out about this topic. You understand a whole lot its almost hard to argue with you (not that I personally would want to…HaHa). You definitely put a fresh spin on a subject which has been written about for ages. Great stuff, just wonderful!
Very insightful, thanks a lot! This article offers great and helpful information to me. I have enjoyed reading it. Great job!
GDPR has I think changed the game altogether!
Wow! Despite the fact that I’m the CEO of a software development company, it was a really interesting article!
Now, in our company, we conduct a three-stage interview for our candidates. First one is to test their soft skills, the second one is to get an understanding of their technical skills and the last one is to test their language skills. Since for the most part we hire junior specialists the most important requirement is higher education. But now, after reading this article, I’m thinking about revising the hiring process in our company. Thank you for great insight! In addition, we are now looking for .NET developers to work remotely, so if somebody are interested in work, please fill the form in our website https://anuitex.com/. Maybe by that time we will try all the insights from the article in life 😀
Thank you for sharing hiring data and the analysis. It’s a rare thing when HR departments conduct such kind of researches on the hiring process, collect data, and make conclusions based on it.
Reading this article gives me lots of important information about recruiters of software development companies. I’ve just cleared my post graduate course and was planning to apply in some reputed firm. Now, I’m aware of all the silly mistakes candidates make and suffer unemployment as well as make hiring a new candidate really a big task.
I notice that the “pedigree” is very heavily biased towards the West Coast, if not entirely (I am not familiar with some of them). Also, those are all very large companies with a very bad work ethic — generally not good places to work! I also note that you only include CS degrees, but not closely related degrees such as Mathematics. And what about other credentials such as patents or publications?
I do believe that a high GPA is an indicator of strong dedication and work ethic. Nobody gets a 4.0 GPA or Summa Cum Laude without a lot of dedicated work over an extended period of time. This is not just a matter of “book smart”, far more goes into getting a GPA that high than just being smart. For example, in my case I took 190 credit hours in four years with a straight 4.0 GPA (120 is required for a Bachelors). That was a brutal schedule, and nothing but the highest level of organization, disciple and dedication made it possible.