I recently had the utterly terrifying experience of giving a guest lecture to an MIT computer science class on technical communication/public speaking. To my relief, things went quite well, and it was awesome to peel back the curtain a bit and give students a perspective on what actually happens inside companies when they’re hiring.
Before my talk, I sent out a survey to see which job-hunt related topics were most interesting, and in addition to the usual stuff about technical interviewing and negotiation, one of the more sought-after topics was how to vet companies during the interview process.
Doing this well is really hard. There’s not much time, you don’t feel like you have much power, and people tend to respond to your questions with rehearsed platitudes. To make things easier, I’ve compiled a list of very specific questions you can ask, verbatim. The purpose of these questions is to be really specific/situational so you can quickly get past the platitudes and make shit get real.
Note that:
It’s a good idea to ask some subset of your interviewers the same questions to see how their answers differ… because the devil is in the deltas.
Don’t waste precious time talking about benefits/salary/vacations/process during interviews – you can get those answers later from HR or whatever.
Bolded questionsare ones I particularly enjoy or find non-obvious.
Without further ado, the questions, broken up by topic, are below. Please use some subset of them at your leisure, and tell me if they helped you! Oh, and maybe don’t say “fuck” in interviews unless you can own it.
Team caliber/culture
How long have you been here?
When you were last interviewing, what were some of your other options, and what made you choose this company?
What is the most fulfilling/exciting/technically complex project that you’ve worked on here so far?
What is something you wish were different about your job?
How often have you moved teams? What made you join the team you’re on right now? If you wanted to move teams, what would need to happen?
(If the company is a startup) When’s the last time you interacted with a founder? What was it regarding? Generally how involved are the founders in the day-to-day?
Engineering
What does a typical day look like? EDIT: What did your day look like yesterday? Was that pretty typical? If not, what does a typical day look like?
What is your stack?
What is the rationale for/story behind this specific stack?
How often do you add new tools to the mix?
Do you tend to roll your own solutions more often or rely on third party tools? What’s the rationale in a specific case?
What kind of test coverage do you have?
Would you describe your engineering culture as more pragmatic or more theoretical?
What portion of your time is spent working on new stuff rather than iterating on existing stuff?
How long are your release cycles?
What’s been the worst technical fuckup that’s happened in the recent past? How did you guys deal with it? What changes were implemented afterwards to make sure it didn’t happen again?
What is the most costly technical decision made early on that the company is living with now?
If possible, also ask for the opportunity toview the source. This may be tricky, it may involve signing some stuff, and you may not be able to do it, but it doesn’t hurt to ask. The best thing, if you can, is to just spend a few days working onsite as a contractor. It’s hard to make time, but boy does that give you some valuable perspective. I’ve had candidates on the brink of accepting offers rapidly drop out after seeing that the day-to-day/codebase/team dynamic was nothing like they expected. And I’ve had people who weren’t sold at all end up loving a place because they got to spend some time with the team.
Product voice/visibility into business side
What are you working on right now? Why/how did that become the thing that you ended up working on?
If you had an idea for something new to build, what would you have to do to make it happen?
What is some of the more meaty new stuff that got pushed in the last release? Where did the idea for that feature originate? Where do product ideas generally come from?
Who are the other major players in this space? What do we have that they don’t? The answer to this one can be useful for getting some idea of what the space looks like and what traction the company in question might have. Most importantly, though, it’ll give you some insight into whether the people at the company care about the product and the business side of things or not and how much they’ve thought about stuff like this.
Attrition
How long does the average engineer stay at the company?
Why have the last few people left?
Entrepreneurship
How many former employees have gone on to found startups?
Was their leaving to do so was generally looked on favorably?
How does company culture encourage entrepreneurship? Specific examples?
Lately, a good number of people have asked me for feedback on their tech recruiting startup ideas, and I’ve noticed that I tend to ask the same questions and give the same advice over and over. Below, I’ve reproduced some of these things. At the end of the day, a lot of my advice is based on the current market climate, where engineering demand severely outstrips supply. I don’t know how long this state of affairs will last, but this state of affairs is precisely why this space is heating up and why it’s so lucrative.
At this point, you might be asking yourself something along the lines of, “Who is this dipshit, and why is she qualified to give advice about starting companies?” I ask myself that every day, and as a disclaimer, I too am working on a product in this space (interviewing.io), so we’ll see if I take my own advice!
1. Engineering hiring isn’t a filtering problem. It’s a sourcing problem.
Many of the people approaching me are eng hiring managers who are considering leaving their job to build tools that fix the hiring problems they encounter in their day-to-day. As a hiring manager, one of the biggest problems you encounter is filtering, namely going through a bunch of candidates and figuring out who’s good. This is really hard. Resumes are pretty low-signal, and technical interviews are fraught with their own set of challenges. But sometimes hiring managers tend to forget that before candidates even get to their part of the process, they’ve chosen to be in the mix, and they have already passed through at least one or two filters. In other words, you’re taking for granted the fact that the people who are crossing your desk want to work at your company in the first place.
Hiring, like sales, is a funnel. At the top, you have your attempts to get people in the door, either through building the kind of brand where people want to apply or through spamming the world or any number of other things. The middle is filtering, where you try to figure out whether the people in your funnel are worth hiring. Unfortunately, filters don’t make people better, so you are constrained by the quality of your sourcing efforts. And, in this market, where engineering supply is severely out of whack with demand, where good people are rarely actively looking for jobs, and where contingency recruiters get at least $25,000 per hire, the biggest problem isn’t filtering through a bunch of engaged job seekers. The problem is engaging them in the first place.
To drive this point home, let’s do a thought experiment. Given the data available on the internets, you could reach out to every engineer at Facebook and/or Google who went to school at MIT and/or Stanford. That data is already out there, and between LinkedIn, Rapportive, Clearbit, Entelo, other candidate search aggregators, and/or a little bit of quick and dirty scripting, doing this isn’t that hard. What’s hard is finding the ones who want to talk to you. Therefore, any product in this space that focuses on filtering isn’t solving the fundamental problem.
2. If you’re building a two-sided marketplace, create value for great engineers up front.
As you saw above, in this market, great engineers are rarely looking for work. Therefore, if you’re building some variation on the theme of a two-sided marketplace that attempts to pair top talent with great companies, you will quickly realize that getting great engineers to sign up is hard. They simply don’t need it and don’t want to be inundated with more noise.
If you do want to engage with the best people (And you do, right? Because it’s easy to go broad if you start elite but really hard to go the other way… kind of like a hiring law of entropy.), think carefully about what value you’re providing up front to people who don’t need you — if you can get that segment interested, everyone else will follow. Hired did this really well by taking advantage of the fact that salary data is pretty opaque and convoluted. In other words, all of a sudden, great engineers had a reason to sign up because, with very little effort (clicking once to sign in with LinkedIn), they could get a pretty good first-pass approximation of their market value that they could then, at the very least, use as leverage and at best, to find a new job. This is a big deal.
How do you apply this to your idea? If there’s some hard-to-find info you can shine a light on (salary data, team structure, etc.), by all means do it. If you can’t do that, then think about convenience. As it stands, interviewing is a pain point. Great people often have many interview loops going on in parallel, different parts of which are more frustrating than others. If you can streamline part of the process, or let the candidates you work with skip some of the drudgery, you’re going to be in good shape.
3. Are you trying to force people into behaviors that run counter to their incentives?
Regardless of the space you’re in, you should be building something your users want, but I can make the pitfalls really concrete in the tech recruiting space. Specifically, many of the people that come to me asking for my opinion on their business idea oversimplify the incentives at play. They assume that everyone just wants to hire the best people and that’s it. However, the world of incentives is complicated, and you have to be mindful of the misalignment of individual incentives/those of the purchasing decision makers relative to the optimal outcomes for organizations. In other words, though everyone wants to hire the best people, unless your product is an unambiguous, direct line to doing that, shit gets hard. To illustrate these points, I’ll go through 2 examples. Both are drawn from reality. The first one is from my own experience, while the second is my analysis of why someone else’s product in this space didn’t pan out.
Incidentally, although in-house recruiters are not the only ones with complicated incentives, they are generally the gatekeepers for figuring out which hiring products to use, so I’ll focus on them here. If you’re selling to recruiters, you have to be able to put yourself in their shoes, and you have to be careful to not oversimplify what their incentives actually are. “Recruiters want to hire more good people” is often a gross oversimplification that causes you to lose a lot of time building the wrong things because you don’t deeply understand your audience. Your other option is to say that you’re going to go around recruiters and sell to a different org within the company, but that’s its own can of worms with its own set of tradeoffs that I’ll save for a future post.
Example 1 – Why presenting great candidates isn’t enough
So, with in-house recruiters, their whole job is to hire good people, right? However, what does “good” really mean? When I was focusing on running a 3rd party recruiting agency, I consistently ran into the same problem when working with in-house recruiters. I’d present a candidate who looked like shit on paper but that I had reason to believe was good (previous work, having run them through technical screen, etc). Recruiters at these companies, by and large, wouldn’t entertain a conversation with these candidates because it was too risky for them. Engineering time is precious, and if you present someone who looks suspect and they don’t work out, you incur a good amount of vitriol internally. If, however, you keep presenting safe candidates, some of whom make it through and some of whom don’t, no one can blame you.
To put it really concretely, I’d expect that as an in-house recruiter, if you presented 10 candidates from Google/Facebook/MIT/Stanford, 8 of whom didn’t get an offer, and 1 of whom did but was clearly never too interested in your company, and 0 of whom got hired, no one would bat an eye. On the other hand, if you presented 10 candidates, all of whom looked kind of weird on paper, 2 of whom got offers, and 1 of whom got hired, you’d probably going to get a stern talking to.1
It’s a bit silly, but that’s how things work. If you’re building a product that surfaces people for recruiters to talk to, think about whether those people are risky bets and how those risky bets affect recruiters’ metrics — recruiters are bound by all sorts of metrics, and how many people they hire is only a small part. So, getting them to make seemingly unsafe, ambiguous choices with no clear return probably isn’t the best way to go.
Example 2 – Why it’s important to understand internal engineer/recruiter dynamics
Here’s another one. Let’s say you’re building a sourcing tool that involves getting the engineers at a given company to hook in their social networks so that your recruiters can then reach out to the people that engineers at the company already know, as those people are likely to be 1) good at stuff because yay referrals and 2) warm-ish leads. Cool idea, right? And it makes sense because recruiters want to hire more good people, right? Unfortunately, as before, it’s not that simple.
While recruiters do want to hire good people, that’s not the only thing they want. There are tons of products coming at them claiming to make their lives easier all the time. Most of these products end up not doing that. Now, in addition to asking them to spend time on something with questionable return, you’re asking them to evangelize said questionable product to engineers, whose participation is necessary for things to work, before the recruiters even have a chance to confirm that the product is, in fact, useful. Add to that the tension/stratification that already tends to exist between a company’s engineers and its in-house recruiters, and you wind up with a tall order. Having to vouch for something before you know it’s great is uncomfortable and weird.
For the record, this product was a real thing, and it was called YesGraph. When I first heard about it, I thought it was an awesome idea, but then I learned that they ended up pivoting away from hiring. I believe that the misalignment of incentives I described is partially to blame.
Incidentally, if you’re curious to read more about the challenges around driving/productizing referrals, I wrote about it at some length on Quora.
4. If your goal is to scale your two-sided marketplace, don’t turn into a middleman by accident.
In any two-sided marketplace, the path of least resistance often involves sitting between the two sides and playing god to make sure that everything that is supposed to happen is happening. You want to make sure that the right people are talking to the right companies and that companies are interviewing your candidates and so forth. Sure, down the line, you’re going to build an automated system, but for now, you’ve gotta get in there and make some tweaks.
I am a wholehearted believer in doing things that don’t scale. But, you have to be mindful of whether what you’re doing is going to keep you from going in a scalable direction in the future. Matching users with companies by hand? Great, that makes sense while you learn what works and what doesn’t. But, if you aren’t mindful of it, before you know it, you have a recruiting agency on your hands, just one that happens to have a nice startup-y skin. And, by the time you realize it, you’re too vested in the unscalable status quo to change anything because money’s coming in. And then you have to hire a bunch of recruiters, and then you’re committed. And now, you’re growing linearly with the number of recruiters you hire.
So, sure, do things that don’t scale, but keep asking yourself whether what you’re doing will ever be possible to automate and be mindful of whether you’re creating an infrastructure of middlemen with a vested interest in the status quo. And if you realize that what you’re doing is really hard to automate with technology or solve through crowdsourcing/engaging with your users, then ask yourself whether there’s something else you should be trying.
1 As a footnote to this story, one of the first companies I worked with made a deal with me after seeing the nontraditional kinds of candidates I presented. They said that, though they’d be down to talk to the first 3 candidates I threw their way, if most of them didn’t make it to at least onsite, I was going to be fired. Two years later, this company is one of my favorite clients to do business with — I love their team and, even at the time, I completely empathized with their skepticism. Though it ended up working out well, this kind of deal is rare and getting over the hump was likely helped by the fact that I knew one of the founders.
Like many commission-based jobs, technical recruiting has a pretty low barrier to entry, everything you need to know you can probably learn on the job, and the payouts can be huge. On top of that, having an engineering background can give you a significant edge over your non-technical colleagues. However, it is not an easy field to be successful in, in much the same way that consistent, high magnitude successes in sales are difficult. Confound that difficulty with the terror that comes with striking out on your own, and you’re in for a bumpy ride. Below, I’ll share the most salient things I’ve learned in the process of launching my own technical recruiting firm. Some of these things are obvious, and some, at least for me, were entirely unexpected.
Before getting into the list, one thing I want to stress is that, if you’re thinking about doing this, you shouldn’t quit your day job until you know it’s really something you can do. People, engineers especially, tend to think that technical recruiting is easy money. Certainly, it’s not the hardest job, and it uses a very different part of your brain than writing and designing code, but by no means is it a walk in the park. Therefore, before committing to this new course, if it doesn’t create a conflict of interest with your current job, try placing people part-time while you continue to do whatever it is you’re doing now. See if you can make a placement or two before you go all-in. And, even more importantly, see if it’s something you like doing. Because the day-to-day isn’t always awesome… which brings me to the first item in the list.
1. A good chunk of recruiting is wrangling people. And that part sucks.
When I first got into recruiting, I thought that most of the job would be finding talented engineers and presenting them with great opportunities they wouldn’t have had access to otherwise. Sounds great, right? I thought I’d be getting paid to judge people, unearth the good ones, and rack up karma points for making their lives better.
In reality, a good chunk of the job happens after you find great engineers. You have to convince companies to talk to them because unless they fit a very specific, pedigreed mold, most companies won’t touch them with a 10 foot pole. Following up every few days to make sure that everyone who’s supposed to talk to everyone else is actually talking. Checking in to see what everyone thinks and how they’re feeling. Keeping track of your candidates’ timelines. Potentially getting into shit situations where multiple companies are interested in the same person and trying to figure out how to best recuse yourself so no one thinks you’re an asshole who’s instigating a bidding war while still trying to make sure your engineer gets the best offer they can.
It’s a hot mess. A lot of this job is like being stuck between 2 different, mildly adversarial high school cliques and making sure that, at the end of the day, they both still like you.
At the end of the day, the guys from Hacker School (formerly Hackruiter) said it best when they talked about why they pivoted away from being a recruiting org, so I’ll just quote them here.
[Recruiting is “soul-crushingly awful.”] When the idea first came up to become recruiters, pg [Paul Graham of Y Combinator] warned we’d hate it. He said it’d be miserable grunt work, but worthwhile for what it’d teach us. He was right on all counts.
A few of the many reasons recruiting sucks: You spend all your time having meetings (on the order of dozens a week) and writing emails. You never code. Your meetings and emails consist primarily of either rejecting people or being rejected (or watching people you like get rejected, frequently for dumb reasons). Desperate people lie to you, companies ignore you, and even if you’re ethical and upstanding, most people (understandably) initially distrust you because you’re a recruiter.
Last year, I worked with a really great engineer who told me it was his dream to work in the ed-tech space. He also told me that one of his deal-breakers was working in advertising and that he’d never do it. I set him up at Udacity, and he did an onsite interview. Then, while he was in town, for shits and giggles, he interviewed at an advertising startup where one of his friends was working. That’s the place he ended up choosing.
The truth is people will tell you all manners of lies about where they want to work, what they want to work on, and what’s important to them. But, of course, they’re not lying deliberately. It likely means you’re not asking the right questions, but sometimes knowing what to ask is really hard. For many of the questions you can think of, people will have all sorts of rehearsed answers about what they want to do, but those answer are framed to a specific audience and may not reflect reality at all. Or, a lot of the time, people simply don’t know what they want until they see it.
Because of these roadblocks to getting to the heart of what people want, I’d suggest not dwelling too much on what people say. Instead, pick some interesting companies, and get them to talk to someone who works there. Perhaps the most important thing I’ve learned is that, at the end of the day, one of the biggest parts of a recruiter’s job is to get the right two people in a room together. Regardless of industry or domain or stack or money (within reason of course), chemistry is king. Get the right two people to have the right conversation, and everything else goes out the window.
3. You should write down your principles.
This job is ethically gross. You will be tempted to do all sorts of things that you found to be abhorrent before embarking down the agency recruiting path. And the more you see them being done around you, and if you ever do them yourself, it’s a slippery slope. It’s simple really. Humans are frighteningly adaptable creatures. Scared of public speaking? Give 3 talks. The first one will be panty-wringingly horrific. Your voice will crack, you’ll mumble, and the whole time, you’ll want to vomit. The next one will be nerve-wracking. The last one will mostly be OK. And after that, you’re fine. Same thing applies to offer negotiation, approach anxiety, sex, and mathematical proofs.
And of course, it applies to vile business practices as well. When huge amounts of money are at stake, it’s easy to talk yourself into all sorts of things:
If a candidate you’re working with has an opportunity outside of your lineup that’s clearly better for them, it’s very tempting to try to talk them out of it. Don’t do it.
If a candidate is worth more than one of your clients is offering them, but you just want to close the deal to get your paycheck, don’t do it.
If companies are pressuring you to disclose offer details, but your candidate asks you not to, don’t do it.
If you know a candidate is about to accept a position because they really like their new manager, and you know that that manager is going to be leaving the company really soon, it’s going to be tempting to withhold that info. Don’t do it.
Write down what you won’t do and then keep not doing it because once you start, it’s going to be hard to stop. Which brings me to my next point.
4. Play the long game. Treat your candidates well.
In this market, finding companies who want you to help them hire is a lot easier than finding great engineers who want to work with you. Treat every engineer you work with like a precious commodity. Even if they don’t end up finding jobs through you, if you add value, are helpful, give them info they wouldn’t have had otherwise, counsel them on equity and negotiation, and go out of your way to get them the best opportunities (even if you don’t work with the companies in question), they will remember it. They will tell their friends, and they will come back the next time they’re looking. If you can get to the point where a good chunk of your business is coming from referrals, you’re doing it right.
5. If you’re risk-averse or not OK with never knowing where your next paycheck is coming from, this job is going to destroy you.
Be ready for night-sweats, terror, and creeping anxiety. If you’re working on contingency, especially at the beginning, you will likely go for months before making a hire. I started my firm in February of 2013. I didn’t get my first hire until the end of April. Those first few months were hellish. I’d wake up every morning wondering if I was ever going to make any placements. More immediately terrifying, however, was the fact that I had no idea what I was supposed to spend my time on. When I started out, I had 3 clients (2 of which were companies where I had worked previously), none of which were household names. I had no idea how to attack the chicken-and-egg problem of not having clients and not having engineers. Eventually, of course, I decided to start with the engineers, figure out what they wanted, and then beg, borrow, steal and do whatever it took to get them in front of the right people at companies they might like. But that took a lot of time, and there were never any guarantees. Brace yourself, because man is it rough in the beginning.
Which brings me to my next point.
6. Have a project to keep you sane.
When I started my firm full-time, between the night sweats and the terror that I was never going to place anybody, I was working on what eventually became Lessons from a year’s worth of hiring data. Even when I felt completely paralyzed by self-doubt, I had this one thing to keep me going. I knew that, if I could pull it off, it would be an awesome blog post. So, between sending sourcing emails and hating myself, I would spend the time counting grammatical errors and typos on people’s resumes. That work, tedious as it was, was deterministic. I knew what I needed to do and how to do it. Knowing that and feeling like I was making progress toward an achievable, well-defined goal saved my sanity in those first few months and very likely my husband’s as well.
I also started to write on Quora back then. I later learned that what I was doing was called “content marketing”. At the time, I was just doing something to feel like, despite all the unanswered emails and no hires, I was still making progress. Truth be told, if there is a single entity I can thank for my business surviving, Quora is probably it.
7. Find a way to differentiate yourself. Just having been an engineer helps, but it’s not enough.
Because of the low barrier to entry I mentioned, some of the hardest work you’re going to have to do is going to be around differentiating yourself — while getting into recruiting is easy, staying in it and consistently making good money is hard. If you come from an engineering background, as I mentioned earlier, that will be a huge help for differentiating yourself, but that will only give you a bit of a boost. At the end of the day, this is a sales job. Great engineers who are shitty salespeople will not do well at recruiting. Great salespeople with no eng background will likely do well. To that end, you’re going to have to spend time promoting yourself, whether it’s through writing, giving talks, offering services that other recruiters can’t, or something else. Self-promotion always felt very ungainly for me, so I decided to focus on data-driven blogging because then, instead of promoting myself, I could promote interesting findings and let them speak for themselves.
8. Invest in tooling as much as possible.
A lot of what you do in this business is administrative work. Anything you can invest in that will cut down on the manual aspect is going to save you time and keep you from forgetting stuff. Some of my favorite tools:
Boomerang – this email tool will make you look to the world like you’re on top of it, even if you’re crumbling slowly on the inside.
Evernote – the be-all and end-all of note taking. For the love of god, don’t take notes in a physical notebook. I did it for a while because I was worried about people hating hearing typing sounds over the phone. Taking notes you can’t search later is dumb.
Lever and/or Asana – for applicant tracking and analytics; which to use depends on your use case.
Expensify – for keeping track of all the business dinners and drinks! (There can be a lot of drinks.)
About a year ago, after looking at the resumes of engineers we had interviewed at TrialPay in 2012, I learned that the strongest signal for whether someone would get an offer was the number of typos and grammatical errors on their resume. On the other hand, where people went to school, their GPA, and highest degree earned didn’t matter at all. These results were pretty unexpected, ran counter to how resumes were normally filtered, and left me scratching my head about how good people are at making value judgments based on resumes, period. So, I decided to run an experiment.
In this experiment, I wanted to see how good engineers and recruiters were at resume-based candidate filtering. Going into it, I was pretty sure that engineers would do a much better job than recruiters. (They are technical! They don’t need to rely on proxies as much!) However, that’s not what happened at all. As it turned out, people were pretty bad at filtering resumes across the board, and after running the numbers, it began to look like resumes might not be a particularly effective filtering tool in the first place.
Setup
The setup was simple. I would:
Take resumes from my collection.
Remove all personally identifying info (name, contact info, dates, etc.).
Show them to a bunch of recruiters and engineers.
For each resume, ask just one question: Would you interview this candidate?
Essentially, each participant saw something like this:
If the participant didn’t want to interview the candidate, they’d have to write a few words about why. If they did want to interview, they also had the option of substantiating their decision, but, in the interest of not fatiguing participants, I didn’t require it.
To make judging easier, I told participants to pretend that they were hiring for a full-stack or back-end web dev role, as appropriate. I also told participants not to worry too much about the candidate’s seniority when making judgments and to assume that the seniority of the role matched the seniority of the candidate.
For each resume, I had a pretty good idea of how strong the engineer in question was, and I split resumes into two strength-based groups. To make this judgment call, I drew on my personal experience — most of the resumes came from candidates I placed (or tried to place) at top-tier startups. In these cases, I knew exactly how the engineer had done in technical interviews, and, more often than not, I had visibility into how they performed on the job afterwards. The remainder of resumes came from engineers I had worked with directly. The question was whether the participants in this experiment could figure out who was who just from the resume.
At this juncture, a disclaimer is in order. Certainly, someone’s subjective hirability based on the experience of one recruiter is not an oracle of engineering ability — with the advent of more data and more rigorous analysis, perhaps these results will be proven untrue. But, you gotta start somewhere. That said, here’s the experiment by the numbers.
I used a total of 51 resumes in this study. 64% belonged to strong candidates.
A total of 152 people participated in the experiment.
Each participant made judgments on 6 randomly selected resumes from the original set of 51, for a total of 716 data points1.
If you want to take the experiment for a whirl yourself, you can do so here.
Participants were broken up into engineers (both engineers involved in hiring and hiring managers themselves) and recruiters (both in-house and agency). There were 46 recruiters (22 in-house and 24 agency) and 106 engineers (20 hiring managers and 86 non-manager engineers who were still involved in hiring).
Results
So, what ended up happening? Below, you can see a comparison of resume scores for both groups of candidates. A resume score is the average of all the votes each resume got, where a ‘no’ counted as 0 and a ‘yes’ vote counted as 1. The dotted line in each box is the mean for each resume group — you can see they’re pretty much the same. The solid line is the median, and the boxes contain the 2nd and 3rd quartiles on either side of it. As you can see, people weren’t very good at this task — what’s pretty alarming is that scores are all over the place, for both strong and less strong candidates.
Mobile users, please click here to view this graph.
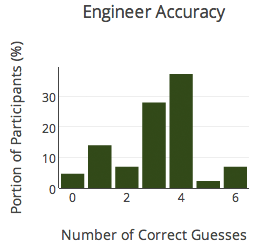
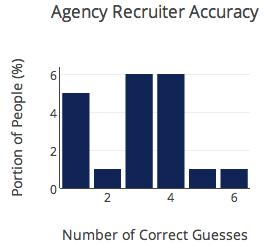
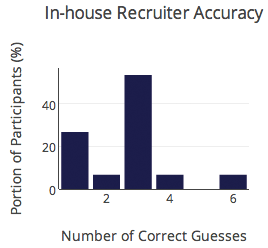
Another way to look at the data is to look at the distribution of accuracy scores. Accuracy in this context refers to how many resumes people were able to tag correctly out of the subset of 6 that they saw. As you can see, results were all over the board.
Mobile users, please click here to view this graph.
On average, participants guessed correctly 53% of the time. This was pretty surprising, and at the risk of being glib, according to these results, when a good chunk of people involved in hiring make resume judgments, they might as well be flipping a coin.
What about performance broken down by participant group? Here’s the breakdown:
Agency recruiters – 56%
Engineers – 54%
In-house recruiters – 52%
Eng hiring managers – 48%
None of the differences between participant groups were statistically significant. In other words, all groups did equally poorly. For each group, you can see how well people did below.
To try to understand whether people really were this bad at the task or whether perhaps the task itself was flawed, I ran some more stats. One thing I wanted to understand, in particular, was whether inter-rater agreement was high. In other words, when rating resumes, were participants disagreeing with each other more often than you’d expect to happen by chance? If so, then even if my criteria for whether each resume belonged to a strong candidate wasn’t perfect, the results would still be compelling — no matter how you slice it, if people involved in hiring consistently can’t come to a consensus, then something about the task at hand is too ambiguous.
The test I used to gauge inter-rater agreement is called Fleiss’ kappa. The result is on the following scale of -1 to 1:
-1 perfect disagreement; no rater agrees with any other
0 random; the raters might as well have been flipping a coin
1 perfect agreement; the raters all agree with one another
Fleiss’ kappa for this data set was 0.13. 0.13 is close to zero, implying just mildly better than coin flip. In other words, the task of making value judgments based on these resumes was likely too ambiguous for humans to do well on with the given information alone.
TL;DR Resumes might actually suck.
Some interesting patterns
In addition to the finding out that people aren’t good at judging resumes, I was able to uncover a few interesting patterns.
Times didn’t matter
We’ve all heard of and were probably a bit incredulous about the study that showed recruiters spend less than 10 seconds on a resume on average. In this experiment, people took a lot longer to make value judgments. People took a median of 1 minute and 40 seconds per resume. In-house recruiters were fastest, and agency recruiters were slowest. However, how long someone spent looking at a resume appeared to have no bearing, overall, on whether they’d guess correctly.
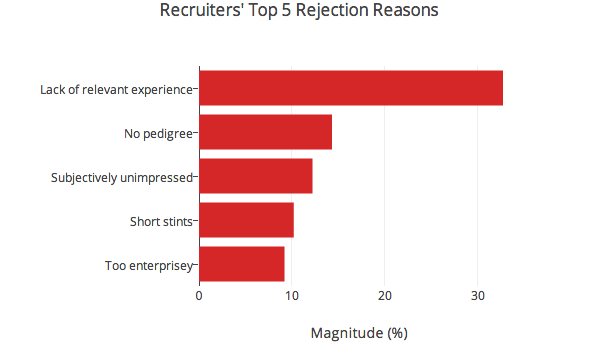
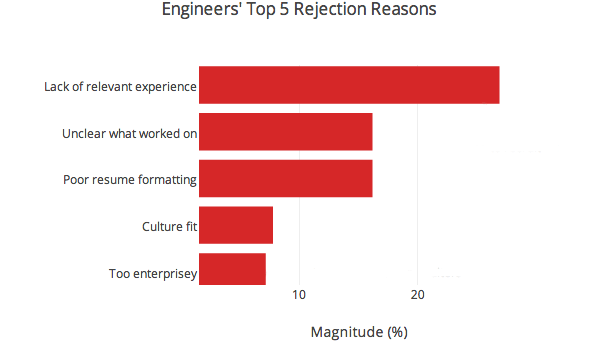
Different things mattered to engineers and recruiters
Whenever a participant deemed a candidate not worth interviewing, they had to substantiate their decision. Though these criteria are clearly not the be-all and end-all of resume filtering — if they were, people would have done better — it was interesting to see that engineers and recruiters were looking for different things.2
Incidentally, lack of relevant experience didn’t refer to lack of experience with a specific stack. Verbatim rejection reasons under this category tended to say stuff like “projects not extensive enough”, “lack of core computer science”, or “a lot of academic projects around EE, not a lot on the resume about programming or web development”. Culture fit in the engineering graph denotes concerns about engineering culture fit, rather than culture fit overall. This could be anything from concern that someone used to working with Microsoft technologies might not be at home in a RoR shop to worrying that the candidate is too much of a hacker to write clean, maintainable code.
Different groups did better on different kinds of resumes
First of all, and not surprisingly, engineers tended to do slightly better on resumes that had projects. Engineers also tended to do better on resumes that included detailed and clear explanations of what the candidate worked on. To get an idea of what I mean by detailed and clear explanations, take a look at the two versions below (source: Lessons from a year’s worth of hiring data). The first description can apply to pretty much any software engineering project, whereas after reading the second, you have a pretty good idea of what the candidate worked on.
Recruiters, on the other hand, tended to do better with candidates from top companies. This also makes sense. Agency recruiters deal with a huge, disparate candidate set while also dealing with a large number of companies in parallel. They’re going to have a lot of good breadth-first insight including which companies have the highest engineering bar, which companies recently had layoffs, which teams within a specific company are the strongest, and so on.
Resumes just aren’t that useful
So, why are people pretty bad at this task? As we saw above, it may not be a matter of being good or bad at judging resumes but rather a matter of the task itself being flawed — at the end of the day, the resume is a low-signal document.
If we’re honest, no one really knows how to write resumes particularly well. Many people get their first resume writing tips from their university’s career services department, which is staffed with people who’ve never held a job in the field they’re advising for. Shit, some of the most fervent resume advice I ever got was from a technical recruiter, who insisted that I list every technology I’d ever worked with on every single undergrad research project I’d ever done. I left his office in a cold sweaty panic, desperately trying to remember what version of Apache MIT had been running at the time.
Very smart people, who are otherwise fantastic writers, seem to check every ounce of intuition and personality at the door and churn out soulless documents expounding their experience with the software development life cycle or whatever… because they’re scared that sounding like a human being on their resume or not peppering it with enough keywords will eliminate them from the applicant pool before an engineer even has the chance to look at it.
Writing aside, reading resumes is a shitty and largely thankless task. If it’s not your job, it’s a distraction that you want to get over with so you can go back to writing code. And if it is your job, you probably have a huge stack to get through, so it’s going to be hard to do deep dives into people’s work and projects, even if you’re technical enough to understand them, provided they even include links to their work in the first place. On top of that, spending more time on a given resume may not even yield a more accurate result, at least according to what I observed in this study.
How to fix top-of-the-funnel filtering
Assuming that my results are reproducible and people, across the board, are really quite bad at filtering resumes, there are a few things we can do to make top-of-the-funnel filtering better. In the short term, improving collaboration across different teams involved in hiring is a good start. As we saw, engineers are better at judging certain kinds of resumes, and recruiters are better at others. If a resume has projects or a GitHub account with content listed, passing it over to an engineer to get a second opinion is probably a good idea. And if a candidate is coming from a company with a strong brand, but one that you’re not too familiar with, getting some insider info from a recruiter might not be the worst thing.
Longer-term, how engineers are filtered fundamentally needs to change. In my TrialPay study, I found that, in addition to grammatical errors, one of the things that mattered most was how clearly people described their work. In this study, I found that engineers were better at making judgments on resumes that included these kinds of descriptions. Given these findings, relying more heavily on a writing sample during the filtering process might be in order. For the writing sample, I am imagining something that isn’t a cover letter — people tend to make those pretty formulaic and don’t talk about anything too personal or interesting. Rather, it should be a concise description of something you worked on recently that you are excited to talk about, as explained to a non-technical audience. I think the non-technical audience aspect is critical because if you can break down complex concepts for a layman to understand, you’re probably a good communicator and actually understand what you worked on. Moreover, recruiters could actually read this description and make valuable judgments about whether the writing is good and whether they understand what the person did.
Honestly, I really hope that the resume dies a grisly death. One of the coolest things about coding is that it doesn’t take much time/effort to determine if someone can perform above some minimum threshold — all you need is the internets and a code editor. Of course, figuring out if someone is great is tough and takes more time, but figuring out if someone meets a minimum standard, mind you the same kind of minimum standard we’re trying to meet when we go through a pile of resumes, is pretty damn fast. And in light of this, relying on low-signal proxies doesn’t make sense at all.
Acknowledgements
A huge thank you to:
All the engineers who let me use their resumes for this experiment
Everyone who participated and took the time to judge resumes
Stan Le for doing all the behind-the-scenes work that made running this experiment possible
All the smart people who were kind enough to proofread this behemoth
1This number is less than 152*6=912 because not everyone who participated evaluated all 6 resumes. 2I created the categories below from participants’ full-text rejection reasons, after the fact.
People often ask me if I’m a talent agent for engineers, in the same way that actors have talent agents in Hollywood. In a lot of ways, the way I work is closer to a talent agent than a traditional recruiter — rather than sourcing for specific positions, I try to find smart people first, figure out what they want, and then, hopefully, give it to them.
However, I’m not a talent agent in the true sense, nor have I ever met any. I really wish the agent model could work, but in this market, it’s not going to happen. Here’s why.
First, some quick definitions. A talent agent is paid by people looking for work. A recruiter is paid by companies looking for people. If someone tells you they’re a talent agent for engineers, ask them where their paychecks are coming from.
Agents make sense when it’s hard to find a job or when the opportunity cost of looking for work is high enough to justify paying someone else. Recruiters make sense when it’s hard to find workers or the opportunity cost of looking for workers is high enough to pay someone else. In some sense, it’s almost like recruiters are talent agents for the companies they’re representing.
Talent agents for actors make a lot of sense for precisely this reason. According to the Bureau of Labor Statistics (BLS), “employment of actors is projected to grow 4 percent from 2012 to 2022, slower than the average [of 11%] for all occupations.”1 By contrast, “employment of software developers is projected to grow 22 percent from 2012 to 2022”2, about twice as fast as the average. To get a better handle on this disparity, I also tried to pull current unemployment figures for each industry. Based on some quick googling, it appears that unemployment for software engineers is somewhere between 1 and 4% depending on the source. For actors, it’s between 27 and 90%. What was particularly telling is that according to BLS, there are something like 67K acting jobs in the U.S. (the figure was for 2010 but based on projected growth, it’s not changing too much). The Screen Actors Guild‐American Federation of Television and Radio Artists (SAG-AFTRA) alone boasts over 165K members3, and The Actors’ Equity Association (union for stage actors) has about 50K members4.
Where competition for a job is extremely fierce, it’s in your interest to pay someone a portion of your salary to legitimize you and help get you the kind of exposure you wouldn’t be able to get yourself. For engineers, because the shortage is in labor and not jobs, paying out a portion of your salary for a task you can easily do yourself doesn’t make much sense. Sure, having to look for work on your own is kind of a pain in the ass, but it’s not something you do that often, maybe once every few years. And, in this market, finding a job, for desirable candidates who would actually be in a position to have talent agents clamoring for them, is not that tough. If you look good on paper and have an in-demand skill set, you can pretty quickly end up with a compelling lineup of offers. Even if you do get a few more offers with an agent, for most people, interview exhaustion sets in at somewhere around 5 on-site interviews. Moreover, from what I’ve been able to observe, most people are looking for a job that’s good enough. After a while, if the company is above some social proof threshold, the work seems interesting, the people are cool, and you’re getting paid well (with the supply/demand curve looking the way it does now, this isn’t currently a problem), then you accept.
I found this out myself when I first started my own recruiting firm. At the time, I really wanted to explore the talent agent model. I was convinced that having engineers pay for an agent’s services would swiftly rectify many of the problems that run rampant in technical recruiting today (e.g. wanton spamming of engineers, misrepresentation of positions, recruiters having a very shallow understanding of the space/companies they’re recruiting for), so I spent the first few months of running my business to talking to engineers and trying to figure out if a talent agent model would work. Engineers were super excited about this. Until I mentioned the part where they’d have to pay me, that is.
It does bear mentioning that freelance engineers do have talent agents (e.g. 10X Management). When you’re a freelancer, you’re switching jobs and often and potentially working several jobs in parallel, and on top of that, your time is split between doing actual work (coding) and drumming up business, so the less time you spend on drumming up business, the more time you can spend doing work that pays. In this model, paying someone to find work for you makes perfect sense because the opportunity cost of not working is high enough to justify the payment.
There are some full-time engineer archetypes for whom having a talent agent might seem to make sense. There are people who still have trouble finding work in the status quo. Examples might be engineers who:
don’t look good on paper but are actually very good
are looking for a really specific niche (e.g. NLP engineer looking to work on high-volume search with a specialty in Asian languages)
However, there are not enough of these people to justify an entire market. In other words, for a lot less effort and a lot more money, you could just focus on more mainstream candidates and get paid by the company.
All that said, I wish the whole talent agent thing could work because then the ethics would align with the money. And that’s kind of the dream, isn’t it?